What AI-driven analytics is—today’s definition, not yesterday’s BI
A plain definition you can use in the boardroom
AI-driven analytics is the practice of turning data into repeatable, measurable decisions by combining advanced machine learning, large language models (LLMs), and automation so insights are not only visible but immediately actionable. Where traditional analytics surfaces what happened, AI-driven analytics prescribes what should happen next and—when appropriate—executes or recommends the action with a clear confidence signal and audit trail. This shifts analytics from a reporting function to a decision function that directly influences revenue, cost and risk outcomes.
Put simply for the boardroom: AI-driven analytics sits on top of your data stack to do three things—sense (gather and update signals in near real-time), sense‑make (infer and prioritise causal drivers using models and LLMs), and decide (deliver next-best-actions or automated workflows with human-in-loop guardrails). For a concise industry framing of this shift, see Gartner’s work on augmented analytics and McKinsey’s guidance on moving analytics into decisioning and execution (examples: Gartner and McKinsey discuss the evolution from insight to action—see links below).
How AI-driven analytics differs from traditional dashboards
Traditional BI is optimized for visibility: dashboards, slice-and-dice exploration, and historical reporting. It answers “what happened” and “who did what.” AI-driven analytics adds three capabilities that change how organisations operate:
– Predictive and prescriptive modeling: models estimate likely futures and recommend the most valuable actions, not just correlations. (See Gartner on augmented analytics for context.)
– Natural, contextual interfaces: LLMs and conversational interfaces let business users query data in plain language and receive synthesized, prioritized recommendations rather than raw charts. Microsoft and others have demonstrated how copilots are embedding this capability into BI tools. Source: Microsoft Power BI Copilot announcement — https://powerbi.microsoft.com/
– Closed-loop activation: analytics feeds actionable triggers into CRM, pricing engines, supply-chain systems or automation platforms so the insight becomes an applied decision (either automated or routed to a human with recommended steps). In short, analytics moves from “inform” to “influence” and finally to “act.”
For practical differences, Harvard Business Review and other industry pieces highlight when to trust AI for decisions and how human oversight should be integrated into automated decision paths. See HBR on decision trust and design: https://hbr.org/2019/12/when-to-trust-ai-with-your-decisions
What changed: LLMs, agents, and decision automation
Three recent technology shifts made today’s AI-driven analytics both possible and practical:
– Large language models (LLMs): LLMs synthesize disparate signals—logs, transactional data, customer feedback, and external news—into human‑readable narratives, hypotheses and ranked recommendations. That reduces interpretation time and helps align technical outputs to business priorities. OpenAI and other providers have published how LLMs can be extended into task-specific tools and interfaces. Example: OpenAI’s “GPTs” and platform approaches — https://openai.com/blog/introducing-gpts
– Agentic systems: software agents can now orchestrate multi-step processes—pull data, run models, call an API, update a CRM and create a ticket—closing the loop between insight and execution. Agents are the glue that converts a recommendation into a measurable change in operations.
– Decision automation and orchestration: rule engines, decisioning layers and workflow automation platforms let organisations define where to automate, where to require human approval, and how to measure outcomes. Google Cloud and other vendors describe these capabilities under “decision intelligence” and workflow automation, framing how analytics becomes embedded in business processes. See Google Cloud on decision intelligence: https://cloud.google.com/solutions/decision-intelligence
Together these elements let organisations build decision systems that are auditable, monitored, and iteratively improved—so analytics becomes a sustainable value engine rather than a one‑off reporting project.
The practical implication for leadership: the question is no longer “Do we have dashboards?” but “Which decisions will we close the loop on first, how will we measure lift, and what guardrails will keep outcomes safe and explainable?” That is the hinge between an analytics capability that talks and one that moves the business—and it leads naturally into concrete, high‑ROI plays you can pilot next.
Five high-ROI AI-driven analytics plays with measurable lift
Retention and LTV: voice-of-customer analytics and AI customer success (−30% churn, +10% NRR)
“Customer Retention: GenAI analytics & success platforms increase LTV, reduce churn (-30%), and increase revenue (+20%). GenAI call centre assistants boost upselling and cross-selling by (+15%) and increase customer satisfaction (+25%).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Why it matters: improving retention compounds revenue and reduces CAC pressure — small percentage moves in churn and NRR compound quickly into valuation multiple expansion. The highest-ROI programs combine automated voice/text sentiment analysis, product-usage signals and a customer-success decision engine that recommends the next-best outreach or automated recovery flow.
How to pilot: run a 60-day experiment where AI-driven sentiment flags top 5% at-risk accounts and triggers tailored playbooks (human + automated touches). Track: churn rate of flagged cohort, change in NRR, CSAT and uplift in renewal/upsell conversion.
Pipeline and conversion: AI sales agents and buyer-intent data (+32% close rate, −40% cycle time)
“Sales Uplift: AI agents and analytics tools reduce CAC, enhance close rates (+32%), shorten sales cycles (40%), and increase revenue (+50%).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Why it matters: improving pipeline quality and conversion directly lifts top-line with limited incremental spend. Buyer-intent signals find high-propensity prospects off‑channel; AI agents qualify, personalise outreach and automate CRM updates, freeing reps to close.
How to pilot: instrument a rep pod with intent feeds + an AI qualification agent for 30–60 days. Measure: close rate, average sales cycle length, lead-to-opportunity conversion, and CAC for the tested cohort.
Pricing and mix: dynamic pricing and recommendation engines (+30% AOV, 2–5x profit gains)
“Dynamic pricing and recommendation engines can lift average order value up to ~30% and deliver 2–5x profit gains; case studies show double-digit revenue lifts (10–15%) from personalized recommendations.” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Why it matters: smarter pricing and personalised offers extract latent willingness-to-pay and lift margins. Recommendation engines increase basket size and lifetime value; dynamic price rules capture demand-side opportunities in real time.
How to pilot: deploy a recommendation widget and a soft dynamic-pricing A/B test on a high‑traffic product set for 30–60 days. Measure: AOV, conversion rate, gross margin per transaction and incremental profit contribution.
Uptime and supply: predictive maintenance and supply chain optimization (−50% downtime, −25% costs)
Why it matters: operations-focused analytics translate into large cost and capacity gains. Predictive maintenance and inventory/supply‑chain optimisation reduce unplanned downtime, avoid rush freight, and shrink working capital — all of which improve EBITDA and capacity to grow without capital spend.
How to pilot: start with a single critical asset line or supplier flow. Combine sensor/telemetry signals with anomaly detection and a prescriptive playbook that schedules targeted interventions. Track: unplanned downtime, mean time between failures, maintenance cost, and supply‑chain fulfilment costs.
Trust as a growth enabler: IP/data protection embedded in analytics (ISO 27002, SOC 2, NIST 2.0)
Why it matters: security and defensible data practices are no longer a checkbox — they unlock customers, reduce diligence friction and can directly affect deal value. Embedding security-by-design into analytics (access controls, lineage, logging and incident response) converts risk reduction into buyer confidence and faster commercial conversations.
How to pilot: map high-value data flows for a single analytics product, implement access controls, logging and a compliance checklist aligned to SOC 2 or ISO 27002, and publish a short SOC- or ISO‑aligned evidence pack for sales. Track: time to contract, sales objections resolved, and any reduction in required contractual security concessions.
Each of these plays is chosen for clarity of measurement and speed to value: pick one where you already have clean signals, run a short, instrumented pilot, and measure lift against clear KPIs. Once you see repeatable lift, the next step is to build the minimal technology and governance layers that turn these pilots into automated, auditable business decisions — and that is where the organisational stack and activation patterns become critical.
From data to decisions: the minimal stack for AI-driven analytics
Data foundations: quality, lineage, and real-time signals
At the base of any decision-grade analytics system is a disciplined data foundation. That means reliable ingestion, clear lineage, and a mix of historical and streaming signals so models see current context.
Core elements:
Quick checklist for pilots: confirm owners for top 5 datasets, establish freshness SLOs, and instrument a lightweight data health dashboard that feeds into decision readiness reviews.
Model and agent layer: ML, LLMs, and task-specific copilots
This layer converts signals into intent and ranked actions. It combines classical ML (propensity, forecasting, anomaly detection), embeddings/LLMs (contextual synthesis and explanation) and lightweight agents or copilots that package outputs for users or systems.
Design priorities:
KPIs: model precision/recall where applicable, calibration of confidence scores, and latency from signal to recommended action.
Activation: decisioning, next-best-action, and workflow automation
Activation is where insight becomes impact. A minimal activation layer exposes well-governed APIs, decision rules, and orchestration so recommendations can be tested, approved, or executed automatically.
Core capabilities:
Measure success by conversion of recommendations into actions, measured lift versus control, and time-to-close-the-loop from insight to execution.
Security-by-design: mapping analytics to ISO 27002, SOC 2, and NIST 2.0
Security and compliance must be built into the stack—not bolted on. Minimal requirements include role-based access, data classification, encrypted transport and storage, and automated evidence collection to demonstrate controls.
Practical steps:
Guardrails: human-in-the-loop, explainability, and monitoring
Guardrails convert automation into trusted automation. Combine human review, explainability outputs, continuous monitoring and rollbacks so decisions remain safe and interpretable.
Essential guardrail elements:
Operational KPIs should include false-positive/negative rates for automated actions, time-to-detect model issues, and the ratio of automated-to-human-approved decisions.
Put simply: start with clean, well-instrumented data; layer modular models and small agents that synthesize recommendations; activate through auditable decisioning and workflows; secure everything to expected standards; and protect outcomes with human-in-loop guardrails and continuous monitoring. Once those pieces are in place, you can move from isolated experiments to repeatable pipelines that prove business lift and scale reliably into production—setting you up to run short, measurable pilots that expand into company-wide impact.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
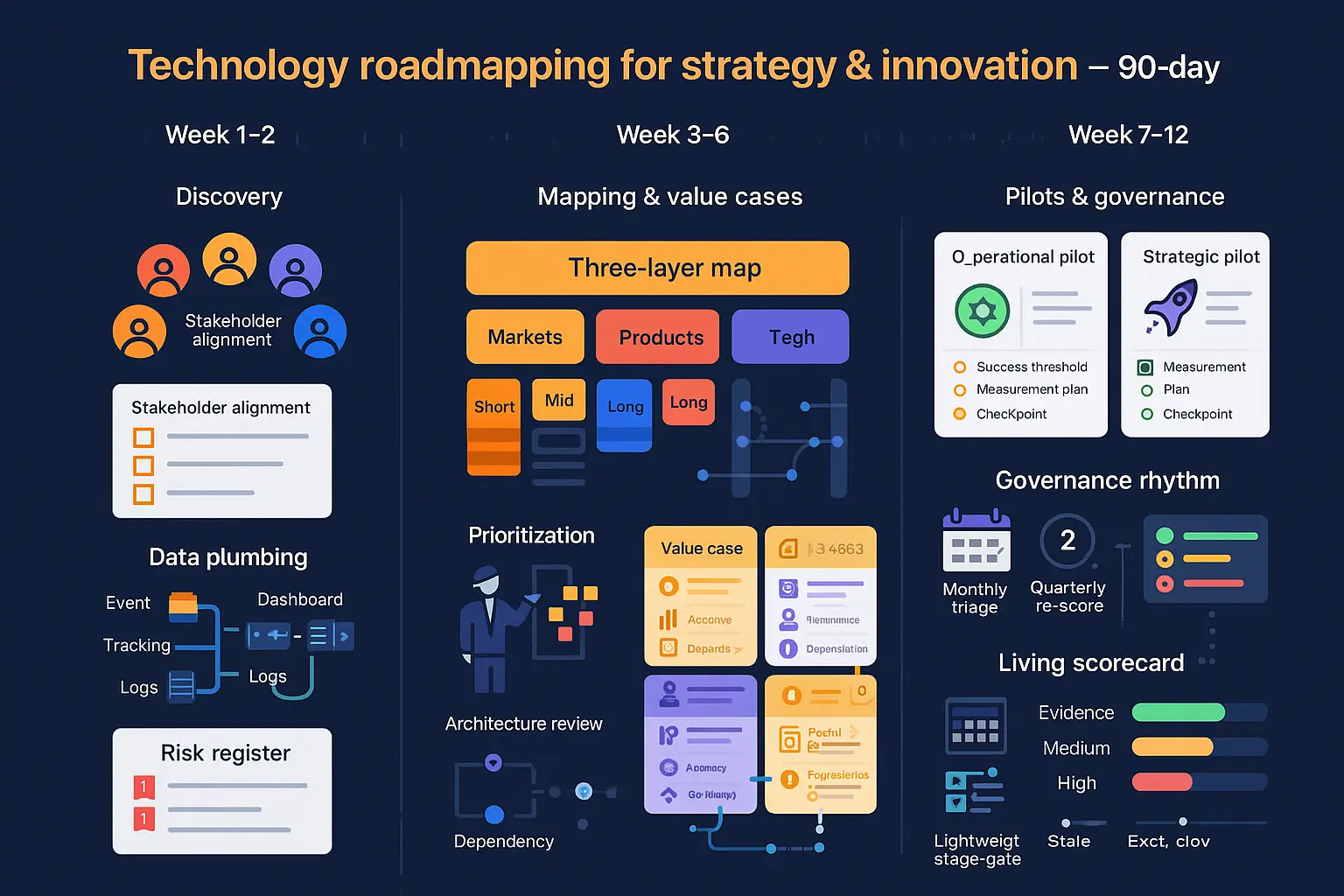
A 90‑day rollout plan for AI-driven analytics (with KPIs)
Days 0–30: baselines, quick wins, and data readiness checklist
Goal: prove the team can move from idea to measurement within 30 days. Focus on alignment, rapid instrumentation and one or two high-probability quick wins that require minimal engineering.
Days 31–60: pilots in pricing, churn, or maintenance with owners and SLAs
Goal: run 1–3 focused pilots that test the hypothesis, measure lift, and validate operational integration.
Days 61–90: scale to production, automate actions, and measure lift
Goal: convert successful pilots into repeatable production flows and quantify business impact against baseline.
Scorecard: churn, AOV, CSAT, downtime, cycle time, and security posture
What to measure and how to present it:
Reporting cadence: a two‑page weekly scoreboard for the steering committee (top-line KPIs, one-page experiment status), a detailed biweekly data & model review, and a full 90‑day executive summary with recommendations and scale plan.
Governance and people: success depends as much on clearly assigned ownership and decision rights as on technology. Keep a small cross-functional squad per pilot (product, data engineering, ML, operations, security, and the business owner) and require documented SLAs for each role.
When pilots show repeatable, audited lift and the scorecard demonstrates durable improvements (and acceptable risk posture), you’ll have the evidence and playbooks needed to expand the program across additional use cases and to translate operational gains into strategic value for stakeholders.
Board outcomes: how AI-driven analytics compounds valuation
Revenue growth: +10–50% via pricing, recommendations, and AI-led sales
AI-driven analytics turns latent signals into recurring revenue opportunities. By personalising offers, identifying high-intent buyers earlier and recommending the right product or price at the right moment, analytics begins to shift conversion, basket size and renewal behaviour. For boards, the key question is whether incremental revenue is predictable and repeatable: pilots should demonstrate a causal uplift, with an evidence trail from signal → recommendation → action → outcome.
What the board needs to see: a clear baseline, controlled experiments or holdouts, end‑to‑end attribution of uplift, and an extrapolation model that translates short-term pilot results into medium-term revenue impact under conservative assumptions.
Cost and efficiency: −20–70% in ops through defect cuts, automation, and energy savings
Operational analytics compresses cost-per-output by preventing failures, automating routine decisions and reallocating human effort to higher-value work. The value is twofold: direct savings (fewer defects, less downtime, lower fulfilment costs) and leverage (scale revenue without linear increases in fixed costs).
For governance, boards should focus on unit economics — cost per transaction, cost per repair, labour hours per output — and monitor both leading indicators (anomalies detected, automated actions executed) and lagging results (cost reduction, margin improvement). Payback timelines and sensitivity to volume or seasonal changes must be explicit.
Risk reduction: breach avoidance, compliance readiness, and defendable IP
Embedding security, lineage and access controls into analytics reduces downside risk that can erode valuation. Demonstrable controls over sensitive data, audit trails for automated decisions and defensible procedures for IP created by models all make the business less risky to acquirers and investors.
Boards should expect a security posture that maps to recognised standards (internal or external), readouts on incidents and near-misses, and a documented approach to protecting model IP and data assets. Risk reduction is often valued through lower diligence friction and reduced indemnity exposure in transactions.
What to show investors: evidence, benchmarks, and repeatable playbooks
Investors rewarded by AI-driven analytics want three things: evidence that the tech moved a business metric, credible benchmarks that place that lift in market context, and a repeatable playbook that scales across business units or geographies. A tidy package should include experiment results, production monitoring dashboards, cost-of-deployment and run-rate economics, and a roadmap for scaling.
Concrete investor artefacts to prepare: a two‑page executive summary with baseline vs lift and confidence intervals; a short technical appendix covering data lineage, model validation and guardrails; an operational runbook showing owners, SLAs and rollback paths; and a scaling plan that converts pilot KPIs into conservative run-rate estimates.
Ultimately, boards convert analytics outcomes into valuation by demanding disciplined measurement, strict governance and reproducible processes: when pilots reliably deliver measurable lift and those lifts are protected by secure, auditable controls, the narrative moves from “potential” to “realised value.” That progression is what changes multiples and shortens paths to value realisation.
Good strategy shouldn’t live in a slide deck. It should turn into revenue, keep customers coming back, and make the business harder to knock off course. That’s what modern digital consulting is for: practical work that moves the needle — fast.
If you need a wake-up call, here are two that matter. First: buyers are doing most of the homework before they talk to you — research shows B2B buyers are nearly 70% through the purchasing process before engaging sellers, and often reach out only once they’ve already picked a preferred vendor (source: 6sense / DemandGen Report). Read the study summary.
Second: trust and data protection aren’t optional. The average cost of a data breach in 2023 was measured in the millions — roughly $4.45M — which is the kind of hit that can erase growth gains and scare away buyers and investors (source: IBM Cost of a Data Breach Report 2023). See the report.
So what does a useful digital consulting engagement look like? In this post we’ll skip the jargon and the long proposals. You’ll get a playbook for delivering pilots (not slideware), three concrete value levers — acquire faster, retain longer, de‑risk smarter — and a realistic 90‑day roadmap to start seeing results. Expect practical examples (AI-first sales, analytics for retention, and IP/data controls that protect value) and clear metrics you can use the week after our work begins.
If you’re tired of plans that go nowhere, read on — this is about turning digital strategy into real, measurable outcomes: more revenue, happier customers, and a business that holds up when things get rough.
What modern digital consulting services include (and what they don’t)
From slideware to shipped outcomes: deliver pilots, not decks
Modern digital consulting is judged by what ships, not what looks good in a boardroom. That means short, focused pilots that prove a hypothesis, integrate with live systems, and deliver measurable value — even if scope is intentionally limited. A pilot should have a clear success definition, a data-backed baseline, and a fast feedback loop so you can learn, iterate, and either scale or stop with confidence.
Deliverables from a contemporary engagement tend to be working software, tracked metrics, trained users, playbooks, and operational runbooks — not a thick binder of recommendations. Consultants who stay with you through initial deployment and hand over repeatable processes and tooling earn more trust than those who only produce slideware. Equally important: pilots should include a lightweight governance plan so outcomes are sustainable after consultants step back.
What modern consulting doesn’t do is substitute polished presentations for implementation. Long, speculative roadmaps that never meet customers, or “strategy-only” projects without defined owners and success metrics, leave teams with optimism but no traction. Good consulting replaces ambiguity with a sequence of rapid, measurable bets.
Three value levers: acquire faster, retain longer, de‑risk smarter
Digital consulting focuses on three practical levers that translate strategy into commercial outcomes. The first is acquisition: creating repeatable, predictable ways to win customers faster — by tightening funnel conversion, cutting friction in buying paths, and making outreach and content more relevant to buyer intent. Acquisition work emphasizes speed to pipeline and tangible improvements to close rates and cycle time.
The second lever is retention: turning first purchases into lasting revenue. This covers product and experience improvements, proactive customer success programs, feedback-derived roadmaps, and operational tooling that surfaces at-risk customers and expansion opportunities. Retention efforts compound value because they increase lifetime value without proportionally rising acquisition cost.
The third lever is de‑risking: protecting the business so value sticks. That includes data governance, basic security and compliance hygiene, IP clarity, and reliability engineering. De‑risking preserves reputation, enables enterprise sales, and reduces the odds of costly interruptions that wipe out growth gains. Effective consulting ties each of these levers to measurable outcomes rather than vague aspirations.
What it doesn’t chase are vanity metrics or one-off experiments disconnected from commercial KPIs. The right projects map directly to a handful of north‑star measures and have a plan to prove ROI within a short window.
Build vs. buy: when to partner with consultants vs. hiring in‑house
Deciding whether to build internally or buy external expertise comes down to three core questions: is this a strategic capability you must own long term; how quickly do you need outcomes; and can you recruit and retain the required talent at competitive cost? If the capability is central to differentiation and you have time to invest, hiring and embedding teams makes sense. If speed, risk reduction, or temporary scale are priorities, partnering or outsourcing is the smarter path.
There are pragmatic hybrid options that combine the best of both worlds: consultants can run rapid pilots, document patterns, and then transfer operations through a build‑operate‑transfer model, or operate managed services while you hire and upskill internal teams. Contracts should be explicit about knowledge transfer, IP ownership, and success criteria so the transition is predictable and clean.
What modern consulting is not: a permanent crutch that masks missing capabilities, nor a one‑time vendor that leaves without enabling the client to sustain results. The best engagements leave the client able to run, extend, and improve the solution independently — or with a clearly scoped partner relationship where that makes sense.
With that clarity on scope, deliverables and decision criteria, the next step is to translate pilots and value levers into a coherent growth engine — rethinking how go‑to‑market, customer experience, and operations work together to turn strategy into sustainable revenue and resilience.
Design your growth engine: AI‑first sales and marketing
Buyer reality: self‑serve research, more stakeholders, omnichannel journeys
“71% of B2B buyers are Millennials or Gen Zers.” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“Buyers are independently researching solutions, completing up to 80% of the buying process before even engaging with a sales rep.” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“The buying process is becoming increasingly complex, with the number of stakeholders involved multiplying by 2-3x in the past 15 years.” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
Those three realities change the rules of engagement. Buyers expect frictionless self‑service, on‑demand content, and highly relevant experiences across web, email, social and paid channels. That requires a go‑to‑market engine that blends real‑time signals, unified customer data, and content automation so prospects can self‑educate — and your team can intervene at the precise moment that drives conversion.
Account‑Based Marketing with hyper‑personalization across web, email, and ads
ABM remains the playbook for high‑value deals, but execution has shifted from manual personalization to programmatic, data‑driven orchestration. Start with firmographic and intent segmentation to prioritize target accounts, then layer dynamic web experiences, tailored email sequences and account‑specific ad creative. Use a Customer Data Platform to stitch signals across systems so every touch — from an ad creative to a product demo — feels like a single, coherent conversation.
Operationally, run small experiments that map a single persona’s journey: custom landing pages, dynamic product recommendations, and personalized creatives delivered by an ad DSP. When conversion lifts predictably, scale the templates across adjacent segments. Automation and templates accelerate personalization without ballooning headcount.
AI sales agents + intent data to lift pipeline and shorten cycles
AI can take on repetitive tasks that steal rep time while surfacing high‑intent prospects earlier in the funnel. Deploy lightweight agents to enrich leads, prioritize outreach, and automate routine CRM actions so sellers spend more time closing and less time logging activity.
“40-50% reduction in manual sales tasks. 30% time savings by automating CRM interaction (IJRPR).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“50% increase in revenue, 40% reduction in sales cycle time (Letticia Adimoha).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
Combine these agents with third‑party intent signals and on‑site behaviour: when intent spikes are detected, trigger hyper‑personalized outreach and an SLA for a sales follow‑up. Keep guardrails for data quality, consent and escalation rules so agents assist — not replace — human judgment. Measure lift by pipeline velocity, qualified lead conversion and average time‑to‑close.
Recommendation engines and dynamic pricing to increase deal size
Upsell and cross‑sell are where margins get real. Recommendation engines surface contextually relevant products during buying moments, while dynamic pricing engines tailor offers to buyer segment, purchase history and deal structure. Together they lift average order value and the probability of multi‑product deals.
Start with a catalogue of high‑impact uplift opportunities (bundles, add‑ons, premium services) and run A/B tests on recommended offers and price bands. Integrate recommendations into sales playbooks and digital checkout flows so sellers and self‑service buyers see the same intelligent prompts.
Metrics that matter: close rate, cycle time, CAC, pipeline velocity, revenue
Focus on a tight set of KPIs that align to commercial outcomes: close rate, average deal size, sales cycle time, CAC and pipeline velocity. Make each experiment accountable to one primary metric and one health metric (e.g., close rate + customer satisfaction). Use cohort analysis to attribute downstream impact — not just first‑touch performance — and bake rapid feedback loops into every pilot.
When acquisition and deal‑size engines are instrumented and measurable, the natural next priority is preserving and expanding that revenue by turning transactions into durable customer relationships through proactive analytics and success operations.
GenAI sentiment analytics to surface churn and expansion signals
“Up to 25% increase in market share (Vorecol).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“20% revenue increase by acting on customer feedback (Vorecol).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“71% of brands reported improved customer loyalty by implementing personalization, 5% increase in customer retention leads to 25-95% increase in profits (Deloitte), (Netish Sharma).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
Generative AI and modern analytics turn passive feedback into proactive commercial moves. Pull together unstructured inputs — NPS, support transcripts, product telemetry, review sites and sales notes — and run topic + sentiment models to identify patterns that predict churn or expansion. The value is twofold: surface priority accounts at risk, and surface signals that justify targeted expansion plays (new features, bundles, or tailored pricing).
Implementation should be iterative: start with a labelled sample from support logs and demos, validate predictive signals against a 60–90 day churn window, then automate alerts and recommended plays. Pair signals with a clear owner and SLA so insights convert into outreach, product fixes, or onboarding improvements — not just dashboards.
CX assistants that raise CSAT and enable faster, smarter support
“20-25% increase in Customer Satisfaction (CSAT) (CHCG).” — Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
“30% reduction in customer churn (CHCG).” — Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
“15% boost in upselling & cross-selling (CHCG).” — Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
AI assistants in contact centres and chat channels cut friction and speed resolution. Practical wins include real‑time agent prompts, summarised case histories, automated post‑call wrap‑ups and next‑best‑action suggestions. When assistants handle routine tasks and surface commercial opportunities, CSAT rises and churn falls — and support becomes a growth channel rather than a cost centre.
To deploy safely, integrate assistants with existing CRM and ticketing, set conservative confidence thresholds for autonomous replies, and instrument fallback routes to human agents. Track outcomes by time‑to‑resolve, first‑contact resolution, CSAT and subsequent upsell rates to quantify business impact.
Customer success platforms for proactive renewals and upsells
“10% increase in Net Revenue Retention (NRR) (Gainsight).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
“8.1% increase in renewal bookings by adopting account prioritizer (Suvendu Jena).” — B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
Modern customer success stacks centralise usage telemetry, support activity, commercial terms and engagement signals to produce automated health scores and playbooks. The goal is proactive outreach: fix at‑risk accounts before they churn, and execute context‑driven expansion plays where product usage signals an opportunity.
Start by defining the components of health (product usage, support volume, NPS trend, contract milestones), validate the health model against historical churn, and build automated nudges and playbooks for the CS team. A lightweight orchestration layer should trigger tailored emails, in-app guidance, or human outreach depending on score and segment.
Retention programs live or die by a few north‑star metrics. Net Revenue Retention (NRR) captures whether existing customers compound revenue; churn rate and cohort LTV show whether acquisition investments are sticking; expansion ARR measures how well success and product-led motions scale value per customer. Make these the cadence of reporting, and require every retention experiment to map back to one primary north‑star and one supporting metric.
Operational checklist: instrument event‑level telemetry, store canonical customer IDs across systems, build attribution cohorts, and review impact weekly during pilots and monthly at a strategic level. Use A/B tests for playbook changes and measure both lift and lift sustainability.
When analytics, assistants and CS platforms are coordinated, retention becomes a growth engine that amplifies acquisition. The final step is to lock that value in — not just with workflows, but with the governance, data controls and IP protections that make recurring revenue reliable and defensible.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Why security earns revenue: trust, win rates, and higher valuation
“Protecting IP and customer data materially affects valuation: the average cost of a data breach was $4.24M in 2023, GDPR fines can reach up to 4% of annual revenue, and strong IP/data protection increases buyer trust and valuation multiples.” — Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Security and IP protection are not just cost centres — they are commercial enablers. Buyers and enterprise procurement teams treat certifications, documented controls and incident readiness as gating criteria for deals. A demonstrable security posture shortens procurement cycles, unlocks larger contracts and supports premium pricing; conversely, breaches and compliance failures destroy trust and can erase value overnight.
Practically, protectable IP (code, models, algorithms, process manuals) can be monetised through licensing or carve-outs, while robust data governance reduces regulatory and contractual friction that otherwise limits sales into regulated verticals. Investing in both reduces the risk discount buyers apply at diligence and supports higher valuation multiples at exit.
ISO 27002, SOC 2, and NIST 2.0—what each framework covers
Choose frameworks pragmatically based on buyer expectations and regulatory needs. ISO 27002 (and ISO 27001 for management systems) provides a global best‑practice baseline for information security controls and an auditable management system. SOC 2 focuses on operational controls around security, availability, processing integrity, confidentiality and privacy — and is often required by US enterprise customers. NIST 2.0 (risk‑based guidance) is increasingly adopted by organisations that must demonstrate rigorous incident detection, response, and continuous monitoring, and it can be decisive for public‑sector contracts.
Consulting engagements should map current controls to targeted frameworks, estimate remediation effort, and prioritise controls that unlock revenue (e.g., access controls, encryption, audit trails, incident response, vendor risk). Certification is rarely the goal in isolation — it’s the by‑product of closing capability gaps that customers and acquirers care about.
Proof points: fines avoided, enterprise readiness, contract wins
Show rather than claim: track the commercial outcomes of security work. Typical proof points include enterprise deals won after SOC 2/ISO readiness, procurement approvals accelerated by published controls, fines or incidents avoided through effective monitoring and backup, and successful bids into regulated markets. Case examples — such as vendors winning contracts where competitors were cheaper due to stronger compliance posture — are high‑impact evidence during sales and diligence.
To operationalise this, capture a brief portfolio of outcomes: control gaps closed, certification timelines, example contracts enabled, incident response time improvements, and quantified risk reductions. That portfolio converts technical investment into clear commercial narrative for sales, investors and acquirers.
Implementation checklist: inventory IP and sensitive data, assign ownership, map to prioritized frameworks, run a focused remediation sprint on high‑risk controls (identity, encryption, logging, backups), and package evidence for customers and auditors. When those basics are in place, you can fold security into commercial storytelling and then move quickly to a short, outcome‑driven roadmap that operationalises these controls at pace.
A 90‑day roadmap to results
Days 0–14: discovery, data audit, and KPI baseline (pipeline, NRR, risk)
Kick off with a focused discovery to align stakeholders on one commercial objective and a small set of north‑star KPIs. Confirm executive sponsor, select the working group (sales, marketing, CS, product, IT) and document decision rights for the engagement.
Run a rapid data audit: locate canonical customer identifiers, inventory key data sources (CRM, analytics, product telemetry, support), and validate basic connectivity. At the same time perform a lightweight risk assessment to surface obvious security, privacy or integration blockers that would prevent pilots from running.
Establish baselines for the chosen KPIs and agree the definition and cadence of measurement. Define success criteria for any pilot (minimum lift, adoption threshold, or operational milestone) so decisions after the pilot are binary and fast.
Days 15–45: quick wins—personalized journeys, agent pilots, insight dashboards
Move from assessment to delivery with two or three tightly scoped pilots that target the agreed KPIs. Typical pilots include a hyper‑personalized buyer journey (one vertical or account cluster), an AI sales/engagement agent on a single channel, and a compact insight dashboard that combines the most important signals for daily decision‑making.
Design each pilot with production intent: integrate with live data feeds where possible, limit scope to a single persona or cohort, instrument end‑to‑end tracking, and assign a playbook owner responsible for conversion to standard practice. Run short sprint cycles with weekly demos and a rolling log of issues and learnings.
Deliver operational artifacts alongside code: acceptance criteria, runbooks, training notes and a small set of automated tests or monitoring checks. At pilot close, review results against success criteria and make a go/no‑go decision with a documented recommendation and next steps.
Days 46–90: scale—automation, security governance, playbooks, enablement
For pilots that meet success criteria, move to scale. Replace manual steps with automation, harden integrations, and roll the approach into adjacent segments or accounts. Standardise templates for personalization, outreach cadences, dashboards and retention plays so scaling is repeatable and measurable.
Parallel to scaling, formalise security and compliance workstreams: ensure data handling meets policy, implement access controls, and produce artefacts required by buyers or auditors. Establish monitoring and alerting so product and revenue teams are informed of regressions in real time.
Finish this phase by producing enterprise‑grade playbooks, training materials, and a prioritized backlog for feature improvements. Validate that the organisation can operate the new flows without daily consultant intervention and that KPIs show sustainable movement in the desired direction.
Operating model: build‑operate‑transfer with measurable SLAs
Adopt a build‑operate‑transfer model to balance speed and ownership: consultants build and stabilise, operate while teams absorb knowledge, then transfer responsibility and documentation. Define measurable SLAs for performance, uptime, data freshness and response times that survive the transfer.
Key elements of the operating model include role maps, escalation paths, runbooks, knowledge transfer sessions, and a phased handover schedule. Include commercial clarity around ongoing support — whether retained as managed services, subcontracted, or fully internalised — and align on budgets for sustaining automation and tooling.
Governance should tie back to commercial outcomes: regular KPI reviews, a single source of truth for metrics, and a continuous improvement loop that prioritises efforts by expected business impact. With that operating model in place, the organisation is equipped to convert short‑term wins into lasting revenue, retention and resilience.
AI stopped being a “maybe” last year. Today teams are living the results — but not everyone is turning experiments into dependable business outcomes. That disconnect is exactly where practical AI consulting helps.
Two short evidence points show the gap: a 2024 EY pulse found that 97% of senior business leaders whose organizations are investing in AI report positive ROI from those investments (so the upside is real), while Boston Consulting Group reports that 74% of companies still struggle to achieve and scale AI value — only about 26% have the capabilities to move beyond pilots. (Sources: EY AI Pulse Survey, Dec 2024; BCG: Where’s the value in AI?, Oct 2024.)
That tension — clear ROI in many projects, plus real difficulty scaling safely and quickly — is the reason this guide exists. We’ll walk through what modern AI consulting actually covers in 2025 (strategy, data foundations, build & integration, change enablement, MLOps), show the three tracks that typically pay back fastest, and give a practical delivery playbook you can use to move from idea to live in roughly 90 days.
If you want something concise and useful, keep reading: this isn’t about vendor hype or lofty promises. It’s about measurable returns, responsible AI practices that reduce risk, and faster, repeatable delivery patterns so your next AI project isn’t a pilot — it’s impact you can count on.
What AI consulting services actually include in 2025
Outcome-first strategy and governance (vision, use-case value maps, risk)
Consulting starts by translating business goals into measurable AI outcomes: revenue lift, cost-to-serve reduction, time savings, user‑experience KPIs and risk tolerances. Firms map candidate use cases to value, complexity, and legal/regulatory impact, then prioritize a small set of high‑impact pilots tied to executive sponsorship and clear success metrics.
Governance is woven into the strategy: risk assessments, data and model ownership, approval gates and playbooks for human oversight. Adoptable reference frameworks — for example NIST’s AI Risk Management Framework — are commonly used to standardize risk vocabularies and lifecycle controls (https://www.nist.gov/itl/ai-risk-management-framework).
Data foundations and platform choices (cloud, vector stores, LLMs)
Practical AI programs invest first in reliable data plumbing: ingestion, cataloging, clean labeled datasets, access controls and data contracts so teams can build repeatably. Consulting engagements scope the minimal data estate required for the chosen pilots and recommend a scalable architecture (cloud provider, data lake or lakehouse, streaming sources) that matches security and compliance needs.
Platform choices include selection of LLM providers, embedding engines and vector stores for retrieval-augmented generation. Consultants evaluate trade-offs — performance, latency, cost, vendor lock‑in — and often run short vendor or PoC comparisons. For current guidance on vector-store options and considerations, teams reference recent market reviews (example: overview of vector databases).
Build and integrate: GenAI, analytics, automation, and agents
Delivery covers rapid prototyping (working MVPs) and integration into the business stack: RAG pipelines, APIs, conversational agents, analytics dashboards and automation flows that tie into CRM/ERPs and operational systems. Emphasis is on modular, testable components: prompt templates, embeddings stores, policy/guardrail layers and connector libraries so models can be iterated without disrupting core systems.
Consultants also define integration patterns and deployment checklists so prototypes can move to pilots and production with predictable risk controls — e.g., staged rollout, canarying of agent responses, and fallback human workflows.
Change enablement: training, workflows, and adoption
Technical delivery is only half the work. Consulting includes role‑based training, new or revised workflows, playbooks for human‑in‑the‑loop decisions and internal communications to accelerate adoption. That means build‑and‑learn sessions for frontline teams, manager toolkits for measuring adoption, and success metrics tied to daily operations so stakeholders see immediate value.
Adoption work also covers updating KPIs and performance reviews to reflect augmented roles (for example, sales reps using AI copilots) and designing user feedback loops so product and safety teams can rapidly translate real usage back into model and UX improvements.
MLOps and monitoring: reliability, drift, and cost control
Production-grade AI requires MLOps pipelines that handle model versioning, automated testing, continuous evaluation and rollback. Monitoring focuses on data drift, concept drift, inference quality and operational metrics (latency, error rates). Modern toolchains provide observability for datasets and models so teams can detect issues early and automate retraining or human review.
Controlling costs for LLM‑driven features is a distinct operational discipline: logging usage patterns, caching and response reuse, batching requests, and optimizing prompts. For an up‑to‑date view of the MLOps tool landscape and monitoring best practices, consultants reference current industry surveys and tool guides.
When these five layers are combined — outcome strategy, data foundations, pragmatic build and integration, change enablement, and robust MLOps — organizations can launch AI products faster while keeping governance and costs under control. With the service blueprint in place, the next step is to choose the specific business functions and use cases where early pilots will deliver the clearest, measurable returns and risk‑profile suitable for scaling.
Where AI pays back fastest: three tracks most firms should start with
Customer service
“GenAI customer service agents operate 24/7, and they can resolve ~80% of customer issues, reduce response times substantially, and drive a 20–25% uplift in CSAT with around a 30% reduction in churn.” KEY CHALLENGES FOR CUSTOMER SERVICE (2025) — D-LAB research
Why this pays back: customer service is high-volume, rule-driven and culture-facing — ideal for retrieval-augmented GenAI, knowledge-driven chatbots and agent copilots. Quick wins include deflecting routine queries to self‑service, surfacing next‑best actions for agents, and automating post-call summaries to cut wrap time.
Typical first steps: assemble FAQ and ticket data, deploy an RAG prototype on a limited channel, instrument CSAT and containment metrics, then expand to voice and escalation flows. Measurable impact usually appears in weeks: lower handle times, improved SLA attainment, and visible CSAT gains.
Product development
“Adopting AI into R&D and product workflows can reduce time‑to‑market by ~50% and cut R&D costs by ~30%, helping accelerate launches. Additionally, AI-driven customer and market insights derisk the process of feature prioritization by ensuring that products are customer-centric” Product Leaders Challenges & AI-Powered Solutions — D-LAB research
Why this pays back: product teams use AI to turn signals into prioritized bets — automated competitor intelligence, sentiment analysis from support and reviews, and simulation/optimization in design. Those inputs let teams focus on features that move metrics, not hypotheses.
Typical first steps: wire up user feedback streams (support tickets, reviews, NPS), run a short market‑sensing model to highlight opportunity areas, and pilot a sentiment‑driven roadmap prioritization. Outcomes are faster iterations, fewer wasted features, and lower validation costs.
B2B sales & marketing
“AI sales & marketing agents can produce personalized marketing content at scale, reduce manual sales tasks by 40–50%, save roughly 30% of CRM-related time, and in some cases drive up to ~50% revenue uplift through higher conversion rates and shorter sales cycles.” B2B Sales & Marketing Challenges & AI-Powered Solutions — D-LAB research
Why this pays back: sales and marketing combine high-value targets with repetitive work — lead finding, lead enrichment, outreach personalization, and content scaling. Automating these parts multiplies seller productivity and brings more qualified opportunities into the funnel.
Typical first steps: automate data enrichment and scoring, deploy AI to draft tailored outreach and landing content for top accounts, and instrument funnel metrics so changes to conversion and cycle time are immediately visible. Early pilots often free up seller time and improve pipeline quality within a quarter.
Across all three tracks the pattern is the same: pick a high‑volume, measurable workflow; run a short prototype that combines business data + lightweight RAG or automation; measure a small set of core KPIs; then scale with governance and MLOps. That makes it straightforward to identify the top three use cases to pursue and prepare the organization for a fast, low‑risk rollout.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Weeks 0–2: value discovery and risk framing with measurable KPIs
Assuming your company meets all the requirements to deploy an effective and scalable AI program, kick off with a short, tightly facilitated discovery: confirm the problem, pick the single metric you’ll move, and define a clear success criterion. Run stakeholder interviews (business owner, product, IT, legal/security, operations) and a rapid data sanity check to surface obvious blockers.
Deliverables by day 10–14: a decision pack containing the prioritized use case, target KPI(s), a one‑page risk register, a minimal scope for an MVP, roles and a 90‑day timeline with go/no‑go gates.
Weeks 2–6: data pipelines, guardrails, and working prototype
Move from paper to code: build the minimal data pipeline, implement access controls and anonymization where required, and assemble the prototype stack (model + retrieval, simple UI or API, basic connectors into core systems). Put guardrails in place early — input validation, prompt templates, and a policy layer to intercept unsafe outputs.
Focus on shipping a working prototype that can be exercised with real users or representative data. Deliver technical artifacts: data map, model config, prototype endpoint, basic test cases and an integration checklist for downstream systems.
Weeks 6–10: pilot with users, bias and security testing, success scorecard
Run a controlled pilot with a subset of users or traffic. Capture quantitative KPIs and qualitative feedback, instrument logging for traces and edge cases, and conduct dedicated bias, privacy and security testing. Use human‑in‑the‑loop reviews to catch failures and tune behavior rapidly.
At the pilot close produce a success scorecard: KPI delta vs baseline, usability findings, risk items that must be mitigated, and an operational runbook. Hold a go/no‑go review with business sponsors and compliance to approve production rollout.
Weeks 10–12+: production launch, MLOps, and continuous improvement
Execute a phased production launch: canary a small percent of traffic, monitor SLOs and business KPIs, then ramp. Implement MLOps for model/version management, automated tests, retraining triggers and data‑drift alerts. Establish cost‑control measures for inference (caching, batching, cheaper model fallbacks).
Hand over operational ownership with runbooks, incident playbooks, monitoring dashboards and a prioritized backlog for continuous improvement. Establish a cadence for review — weekly health checks, monthly business reviews, and a quarterly strategy update to expand features and scale safely.
Across the 90 days keep the loop short: ship small, measure fast, and use learnings to harden governance and operational processes so the solution delivers repeatable value. With a production‑ready playbook in place you can shift focus from delivery mechanics to long‑term resilience, governance and measurement to ensure sustained impact.
Trust by design: security, governance, and measuring value
Security and privacy: DAA protection, least‑privilege access, audit trails
Design security and privacy into every phase: limit sensitive data exposure, apply least‑privilege access controls, and record immutable audit trails for data access and model decisions. Use encryption in transit and at rest, strong vendor/data‑processing contracts, and data‑minimization (only surface what the model needs for the use case).
Operationally, enforce role‑based access to datasets and model endpoints, require approvals for production data usage, and instrument logging that ties model outputs back to inputs and user actions so incidents can be investigated. For programmatic risk management and actionable controls, follow established guidance such as NIST’s AI Risk Management Framework and supporting playbooks (see: https://www.nist.gov/itl/ai-risk-management-framework and https://airc.nist.gov/airmf-resources/playbook/).
Responsible AI is practical: publish concise model cards or documentation that explain intended use, limitations and performance slices; run fairness and robustness tests before deployment; and embed human‑in‑the‑loop gates for high‑risk decisions. Explainability tools (feature importance, counterfactuals) and slice‑level evaluation help teams find where models underperform for specific cohorts.
Implement an escalation path for unexpected outputs and a clear policy for when to route to a human reviewer. Use repeatable tests for demographic parity, precision/recall by group, and adversarial or prompt‑injection scenarios as part of the CI pipeline. NIST’s AI RMF is a useful reference for aligning transparency and oversight requirements to organizational risk tolerances (https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf).
Value tracking: CSAT, churn, revenue lift, cost‑to‑serve, model quality
Track both business KPIs and model health metrics. Business KPIs should map directly to the use case (for example, CSAT, churn, conversion rate, time‑to‑resolution or cost‑to‑serve) so you can quantify revenue or cost impact. Model metrics should include accuracy, calibration, prediction distribution, and drift signals for inputs and outputs.
Use A/B testing or canary rollouts to measure causal impact, and instrument dashboards that combine business metrics with model observability (latency, error rates, data and concept drift). For frameworks and practical KPI examples for GenAI and ML systems, see guidance on GenAI KPIs and monitoring best practices (examples: https://cloud.google.com/transform/gen-ai-kpis-measuring-ai-success-deep-dive and https://www.datadoghq.com/blog/ml-model-monitoring-in-production-best-practices/).
Finally, operationalize remediation: define thresholds and automated responses (rollback, degrade to a safe fallback, human review) and run regular post‑launch reviews that reconcile model quality metrics with business outcomes. That way governance and security are not checkboxes but living controls that maintain trust while the system delivers measurable value.
If you’ve been watching markets lately, something feels off compared with the old 60/40 playbook. Valuations are elevated and dispersion between winners and losers is higher than in calmer years — conditions that make static, mean–variance allocations brittle when the next shock arrives.
To put it in numbers: the S&P 500’s forward price/earnings ratio recently sat in the low‑20s (around 22–23), well above several long‑run averages (the 10‑year average is ~18.1), a sign that price moves — not earnings — have driven much of recent gains (source: FactSet). See the original note here: FactSet — Earnings Insight.
At the same time, product economics have shifted: fund fees keep getting squeezed (the asset‑weighted average expense ratio for U.S. funds fell to about 0.34% in 2024), which changes how advisors and managers can charge for active decision‑making and where the value must come from (source: Morningstar). Read more: Morningstar — Fund Fee Study.
Those two trends — stretched valuations and fee compression — are why standard optimizers that only balance expected return and variance often underperform in real life. What we need instead is optimization that treats portfolios as living systems: models that manage drawdown, tail risk, taxes, liquidity and client constraints; that update from real‑time signals and alternative data; and that scale personalization across thousands of accounts without exploding costs.
This article walks through what modern, AI‑driven portfolio optimization actually does (not the buzzword version): the methods that matter, the three‑layer stack of signals → allocation → execution, governance you can trust, and a practical 90‑day blueprint to pilot a resilient, personalized solution that can scale. If you want fewer surprises and portfolios that behave more predictably when markets don’t, keep reading.
From mean-variance to multi-objective: what AI portfolio optimization really does
“Big players like Vanguard are putting pressure in the market by lowering their fees (Vanguard).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
“Current forward P/E ratio for the S&P 500 stands at approximately 23, well above the historical average of 18.1, suggesting that the market might be overvalued based on future earnings expectations.” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
Classic mean–variance (Markowitz) frameworks optimize expected return against variance assuming stable correlations, normal-ish returns and modest trading costs. Those assumptions break down when fees compress, passive flows change market microstructure, and dispersion across sectors and regions rises. In practice this makes single-objective allocations brittle: they chase expected return while under‑estimating drawdown risk, tail events, cost friction and regime shifts. AI moves the conversation from a narrow variance lens to a richer understanding of when and why models fail, and how to adapt in near real time.
Optimize more than return: drawdown, tail risk, taxes, liquidity, and mandates
Modern portfolio optimization treats allocation as a constrained, multi-objective problem. Rather than maximizing an expected return per unit variance, successful systems jointly balance objectives such as limiting maximum drawdown, capping tail loss (CVaR), minimizing realized tax liability, preserving liquidity buffers, and respecting client- or mandate-specific rules. That means portfolios are built to meet business and behavioural goals — e.g., reducing rebalancing turnover for taxable clients, reserving high-liquidity sleeves for stress, or enforcing ESG or regulatory constraints — not just to chase a point estimate of mean return.
Framing allocation as multi-objective lets practitioners surface trade-offs explicitly (risk budget vs. expected alpha vs. tax drag) and produce Pareto-efficient sets of portfolios from which human advisors or downstream automation can choose the profile that best fits each client.
Methods that matter: Bayesian models, reinforcement learning, deep nets, metaheuristics, and causal signals
AI brings a toolbox for multi-objective problems:
– Bayesian and hierarchical models: incorporate parameter uncertainty, shrink noisy estimates, and produce probabilistic forecasts and credible intervals rather than overconfident point predictions.
– Reinforcement learning (RL): learns policies that optimize long-run objectives under transaction costs and path-dependent constraints — useful for dynamic rebalancing and execution strategies that adapt to market regimes.
– Deep learning and representation nets: extract non-linear cross-asset interactions and latent regimes from high-dimensional inputs (order books, factor returns, macro time series) to improve forecast robustness.
– Metaheuristics and multi-objective optimizers (genetic algorithms, NSGA-II, simulated annealing): navigate complex, constrained search spaces to produce Pareto-front solutions that satisfy hard business rules.
– Causal inference and structured models: separate correlation from mechanisms (e.g., policy shocks, earnings surprises) so allocations respond to drivers rather than ephemeral correlations — a key step to avoid overfitting and to support explainability.
Data edge: real-time market data, alt data, and NLP sentiment that update risk faster
AI-powered optimization is only as good as the signals feeding it. Real-time market microstructure (tick and order book data), alternative datasets (credit spreads, flows, commodity inventories) and NLP-derived sentiment from news and filings let models detect regime shifts earlier and re-estimate risk on shorter horizons. Combining high‑frequency risk signals with lower‑frequency fundamental or behavioural inputs produces a layered view of uncertainty: fast signals trigger guardrails or tactical tilts, while slower signals drive strategic allocation.
Importantly, integrating these inputs with cost-aware optimization (explicit slippage, market impact, and tax models) prevents models from proposing paper-only gains that evaporate once execution is considered.
Seen end-to-end, AI portfolio optimization reframes allocation as a living, multi-objective decision process — probabilistic, constraint-aware and execution-conscious — rather than a static solution that returns a single “optimal” weight vector. That perspective leads directly into how to structure the system layers that generate signals, turn signals into allocations, and actually execute those allocations in markets in a robust, auditable way.
The three-layer stack: signals, allocation, and execution
Signal generation: regime detection, feature engineering, and noise-robust forecasts
The top layer is about turning raw information into trustworthy signals. That means building pipelines for regime detection (identify when market dynamics change), robust feature engineering (scale-invariant, de-noised inputs) and models that prioritize stability over short-term accuracy. Good signal design blends multiple horizons: fast signals that catch liquidity shifts and slow signals that capture fundamentals or macro regimes. Equally important are validation layers — signal quality metrics, concept‑drift detectors and simple explainers so humans can sanity‑check what the model “sees.”
Operationally, keep signals modular and versioned: ensemble weak, heterogeneous predictors (statistical factors, time‑series models, NLP sentiment, alt‑data transforms) and expose uncertainty estimates so downstream layers can weight or ignore noisy inputs.
Portfolio construction: constraints, costs, tax-aware optimization, and robust risk control
The allocation layer consumes signals and turns them into tradeable plans under hard business rules. Rather than a single objective, modern construction is multi-objective: balance expected return, drawdown limits, CVaR/tail constraints, turnover budgets, liquidity requirements and tax-awareness for taxable accounts. Models must explicitly encode transaction costs, market impact and any mandate constraints (ESG screens, concentration limits, client-specific exclusions).
Implementation patterns that work: constrained optimisation that returns Pareto sets for different trade-offs; risk budgeting frameworks that allocate volatility or drawdown capacity across sleeves; and scenario-aware optimisers that penalize allocations which perform poorly under stressed paths. Importantly, construction should output not just target weights but also a rebalancing schedule and confidence bands tied to signal uncertainty.
Execution converts target changes into real market actions while minimizing slippage and signalling risk. Build execution strategies that are slippage-aware (use impact models and adaptive participation rates), use dynamic rebalancing bands (only trade when mispricing or probability-of-change justify costs), and choose order types that match liquidity profiles across instruments.
Stress-test execution: run scenario drills that combine extreme market moves with reduced liquidity to measure worst‑case trade costs and timing risk. Include human oversight thresholds for large or illiquid trades and instrument-level dark‑pool or algorithmic routing integrations for improved fills.
Evaluation that holds up: walk-forward, out-of-sample, and paper-trade verification
Robust evaluation closes the loop. Rely on walk‑forward and rolling backtests, strict out‑of-sample splits, and live paper-trading before allocating client capital. Key metrics extend beyond gross returns: net-of-cost performance, realized drawdowns, turnover, and realized tax impact. Monitor model drift with production metrics (signal degradation, change in fill quality, widening of spreads) and trigger retraining or fallbacks when thresholds are exceeded.
Governance practices — model cards, versioned datasets, reproducible pipelines and regular audits — turn evaluations into actionable risk control. Human-in-the-loop checkpoints for final sign-off help balance automation with oversight.
Viewed together, these three layers form a practical, testable stack: signals detect and quantify opportunity and risk; allocation translates that information into constraint-aware plans; and execution delivers outcomes while controlling costs. When each layer is instrumented for monitoring, uncertainty and governance, the system produces repeatable, auditable portfolio behaviors — a necessary foundation before scaling AI-driven advice and operational improvements across many client accounts.
Operational alpha with AI: scale advice, lower costs, keep clients
Advisor co-pilot: ~50% lower cost per account and 10–15 hours saved per week
“50% reduction in cost per account (Lindsey Wilkinson).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
“10-15 hours saved per week by financial advisors (Joyce Moullakis).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
“90% boost in information processing efficiency (Samuel Shen).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
AI co-pilots rewire advisor workflows: automated data gathering, pre-populated client briefs, and scenario generation let advisors focus on judgment and client relationships instead of manual preparation. The net result is a materially lower cost-per-account and faster turnaround on bespoke advice — scaling human expertise without linear headcount increases.
AI financial coach: +35% client engagement with real-time education and next-best actions
“35% improvement in client engagement. (Fredrik Filipsson).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
“40% reduction in call centre wait times (Joyce Moullakis).” Investment Services Industry Challenges & AI-Powered Solutions — D-LAB research
Embedded, real-time coaching (chat, micro-lessons, nudges) keeps clients engaged between reviews and increases adoption of recommended actions. For firms, that drives retention and share-of-wallet — while offloading routine questions from high-cost channels to automated, personalised experiences.
Governance and trust: SOC 2 / NIST-aligned controls and explainable recommendations
Operational alpha only scales if clients and regulators trust the system. Adopt SOC 2 and NIST-aligned controls for data handling and model ops, maintain versioned model cards, and instrument explainability layers that translate model drivers into plain-language rationale. Combine automated monitoring (drift, data quality, performance regressions) with human review gates to ensure AI recommendations remain auditable and defensible.
Deliver near-term value with tactical automations: generate client-ready performance briefs, auto-summarise meeting notes with required compliance disclosures, and surface short scenario briefs that compare “what-if” outcomes. These low-friction features both cut advisor time and improve client experience — proving the value of a larger AI-driven rollout.
When advisor co-pilots, client-facing coaching and strong governance are combined, firms unlock a virtuous cycle: lower operating cost, better client outcomes, and more scalable advice. That operational foundation sets up a practical, time-boxed pilot approach for testing models, data ingestion and human-in-the-loop workflows at scale.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Start by aligning business, compliance and client objectives. Convene a compact steering group (portfolio manager, quant lead, product owner, compliance) and document the pilot scope: target client segments, asset classes, mandate-level constraints and required guardrails. Define clear success metrics up front — for example, net-of-cost performance, drawdown limits, turnover targets, tax-efficiency goals and service-level KPIs for advisors and clients. Establish acceptance criteria and a go/no‑go rubric so the team can make objective decisions at the end of the pilot.
Deliverables: project charter, prioritized success metrics with measurement definitions, stakeholder RACI, initial data inventory and minimum viable tech stack checklist.
Weeks 4–6: ingest market + alt data, validate labels, set model risk management plan
Onboard the minimal data set required to run experiments: price & reference data, factor histories, liquidity/volatility proxies and any selected alternative sources. Build ingestion pipelines with schema validation, automated quality checks and logging. If you use labeled outcomes (e.g., regime tags or event labels), validate them for bias and stability across time.
Parallel to data work, create a model risk management plan: model ownership, version control conventions, test datasets, performance thresholds, rollback triggers and documentation standards. Define privacy, access and encryption controls for sensitive client data.
Deliverables: tested data pipelines, label-validation report, model risk management plan and an environment for reproducible experiments.
Weeks 7–9: train/validate (including causal checks), stress test regimes and liquidity shocks
Run model training and validation using walk‑forward and rolling-window evaluation. Emphasize out-of-sample robustness, conservative hyperparameter choices and uncertainty quantification (confidence intervals, predictive distributions). Include causal or sanity checks to ensure signals respond to plausible drivers rather than spurious correlations.
Design stress tests that combine market regime changes with liquidity deterioration, trading friction and tax events. Translate model outputs into allocation candidates and simulate net-of-cost performance across scenarios. Capture failure modes and build fallback rules (e.g., safe-haven allocation, reduced leverage, or manual sign-off thresholds).
Deliverables: validated models with uncertainty estimates, scenario testing report, allocation simulation outputs and a prioritized list of model limitations to address.
Weeks 10–12: shadow mode with humans-in-the-loop, rollout guardrails, go/no-go
Move into shadow/live-sim mode where the system generates recommendations alongside current production workflows but does not automatically trade. Route recommendations through advisor dashboards and compliance review so humans can evaluate accuracy, clarity and operational fit. Track execution quality by simulating order placement and estimated slippage.
During this phase, implement monitoring: real-time signal-health dashboards, model-drift alerts, execution-cost tracking and business KPIs. Run a formal go/no‑go review using the acceptance criteria set in week 1 — include performance on net-of-cost metrics, risk behaviour under stress, operational readiness and control maturity.
Deliverables: shadow performance report, monitoring dashboards, runbook for incidents, and a documented rollout decision with immediate action items for full-scale deployment or further iteration.
Practical notes for speed: keep the pilot narrowly scoped, instrument everything for observability, prioritise reproducibility and choose conservative default actions for production. With a validated pilot and operational controls in place, you’ll be ready to measure the program against the deeper performance, risk and operating metrics that distinguish long‑term winners.
Metrics that separate winners
Net-of-everything performance: after fees, taxes, slippage, and tracking error
Gross return alone is misleading — the metric that matters is what clients actually keep. Net-of-everything performance subtracts management and trading fees, realized taxes, execution slippage and hedging costs, and measures tracking error versus stated benchmarks or objectives.
Measure this at multiple horizons (month, quarter, rolling 12) and by client cohort (taxable vs tax-advantaged, mandate type). Key visualizations: cumulative net return vs benchmark, waterfall of drag (fees → slippage → taxes), and attribution by source (signals, allocation, execution).
Use this metric as the primary commercial KPI for product viability and advisor adoption: small improvements in net-of-everything performance compound and materially change client retention and sales conversations.
Risk depth: max drawdown, tail loss, turnover, liquidity usage, and model drift
Top performers quantify risk beyond volatility. Core measures include maximum drawdown, tail loss (e.g., stress-period losses or conditional VaR), realized turnover, and liquidity consumption (volume traded vs available market depth). Complement these with model-health signals such as drift in predictive power and increases in forecast errors.
Report both realized and stress-mode metrics: simulated severe scenarios, combined liquidity shrinkage and price shocks, and worst-case execution cost. Dashboards should show recent changes (week-over-week) and long-term profiles so teams detect creeping risk or overfitting early.
Operational triggers (retraining, reduced sizing, human review) should be tied to clear thresholds in these metrics to prevent silent degradation from turning into client-impacting events.
Personalization at scale: retention, share of wallet, advice adoption, NRR
Winning firms translate algorithmic recommendations into measurable client outcomes. Track retention and net revenue retention (NRR) for cohorts exposed to personalized portfolios vs control groups. Measure advice adoption rates (percent of recommended actions executed), changes in client lifetime value, and share-of-wallet shifts over time.
Instrument A/B tests and cohort studies to prove causality: did personalized rebalancing, tax-loss harvesting or tailored communications actually increase engagement and revenue? Combine product metrics (adoption, feature usage) with financial outcomes (flows, cross-sell) to build a business case for scaling.
Present these metrics in cross-functional dashboards so portfolio teams, advisors and commercial leads share a single source of truth about personalization ROI.
Operating leverage: rebalancing cost per account, advisor time saved, compliance incidents
AI wins when it drives scalable operating improvements. Quantify unit economics: rebalancing and custody costs per account, average advisor time spent per review, and automation lift (tasks moved from manual to automated). Track compliance incidents or exception rates as the safety metric that constrains speed-to-scale.
Measure cost trends as adoption grows — aim to show falling marginal cost per account and rising throughput per advisor. Combine time-motion measurements with financial reporting (hours saved × fully loaded cost) to compute program payback and ROI.
Use operating-leverage metrics to prioritise investments (e.g., improve execution automation if rebalancing cost dominates, or invest in explainability if exceptions drive compliance overhead).
Make these metrics actionable: instrument them from day one, show them on live dashboards, and tie them to clear governance rules and product milestones. That empirical discipline — not shiny models alone — is what separates pilots that scale from ones that stall.
If you’ve been part of an AI pilot that never shipped, you’re not alone. A Gartner survey found that, on average, only about 48% of AI projects make it into production — and it takes roughly eight months to move a prototype into a live system (Gartner, May 2024). That gap between promise and impact is where most organizations lose momentum, budget and trust.
Part of the reason is plain: messy foundations. Over 9 in 10 CTOs say technical debt is one of their biggest challenges, and that debt routinely sabotages efforts to scale models into reliable products (Ardoq). Without clear data, ownership, and change plans, a great model is just an experiment on a laptop.
This post is about the bit in the middle — the consulting approach that turns models into measurable value. No fluff about fancy architectures: we focus on outcomes you can measure in months, not years. You’ll get a simple way to triage high‑ROI use cases, a practical 90‑day launch template, field‑tested playbooks for product and revenue teams, plus the must‑have data and MLOps practices that keep improvements in production.
Read on if you want frameworks and checklists you can use next week: how to pick projects that move the needle, how to manage technical debt and change from day one, and how to publish the handful of metrics that earn stakeholder trust. This is about turning prototypes into predictable, repeatable business results.
Lead with value: the AI/ML consulting approach that outperforms
What great projects deliver in 90–180 days: revenue lift, cost-to-serve cuts, retention gains
“High-impact AI projects can deliver measurable value in months: examples include 50% reduction in time-to-market, 30% reduction in R&D costs, up to 25% market-share uplift and 20% revenue increases when paired with targeted product and sentiment analytics.” Product Leaders Challenges & AI-Powered Solutions — D-LAB research
High-performing engagements start by converting ambition into specific, measurable outcomes. In the first 90–180 days the project plan should focus on a tight set of KPIs (revenue upside, cost-to-serve, retention or activation) and on the smallest delivery that proves them: an instrumented model in production, an automated decision that changes user or seller behavior, or a segmentation that drives targeted experiments.
Successful teams prioritize rapid, measurable experiments over long R&D cycles. That means defining baseline metrics, short A/B windows, and clear ownership for both the model and the downstream action (pricing rule, marketing touch, product prioritization). When outcomes — not algorithms — are the North Star, projects produce tangible business improvements quickly and reduce sunk cost risk.
Outcomes over algorithms: decision intelligence, not dashboards
AI consulting that wins is not about building the fanciest model — it’s about changing or validating decisions. Deliverables should include the decision flow (who acts, when, and how), the automation or human-in-the-loop mechanism, and the measurement hooks that prove impact. A dashboard is useful, but only if it triggers repeatable actions that move the needle.
Practical steps consultants should take: map the decision, instrument the data and the action, prioritize interventions by expected lift, and deploy minimal automation that can be iterated. Embed evaluation into the cadence: weekly leading indicators, a 6–8 week adoption and coverage checkpoint, and a 90–180 day ROI review. Keeping the loop short forces learning and allows fast reallocation of effort to the highest-return levers.
When to skip AI: process fixes, low-signal data, or unclear owners
Not every problem needs AI. Skip a model when the root cause is poor process, when data lacks signal, or when there’s no accountable owner to act on model outputs. Common no-go signals are sparse or biased labels, fragmented event capture, or decision processes that cannot be operationalized.
In those cases, invest first in process redesign, instrumentation, and ownership. Simple rule-based automation, data collection pipelines, or clearer SLAs often unlock more value faster and pave the way for future AI. The best consultancies diagnose these gaps upfront and recommend a short remediation roadmap rather than forcing a premature model build.
Leading with value means designing work that produces measurable business outcomes quickly, then scaling what works. That disciplined triage — pick the metric, prove the intervention, and lock in operational ownership — naturally leads to the next step: choosing the highest-ROI use cases and a feasibility-first launch plan.
Pick high-ROI use cases with a simple value–feasibility triage
Score by impact, data readiness, complexity, and risk
Start with a compact scoring sheet you can complete in a single workshop: assign 1–5 points for impact (revenue, margin, retention), data readiness (label quality, coverage, freshness), implementation complexity (systems, integrations, engineering effort) and business risk (privacy, compliance, bias). Sum the scores and use a simple rule: prioritise use cases with high impact and high data readiness, deprioritise those that score low on both.
Keep the scoring practical. Estimate impact with a top-down (market or portfolio) and bottom-up (per-customer or per-transaction) check — even a conservative range is enough to rank initiatives. For data readiness, capture three quick facts: where the labels live, how complete the event stream is, and whether you can join data across sources. Complexity should include both model engineering and the integration work required to operationalize decisions; risk should factor legal, reputational and product-side exposure.
Account for technical debt and change management from day one
“91% of CTOs see this as their biggest challenge (Softtek).” Product Leaders Challenges & AI-Powered Solutions — D-LAB research
“Over 50% of CTOs say technical debt is sabotaging their ability to innovate and grow.” Product Leaders Challenges & AI-Powered Solutions — D-LAB research
Use those realities to adjust feasibility scores upward or downward: a high-impact idea may be infeasible in the short term if plumbing, APIs, or data lineage are missing. Make remediation visible in the project plan — list the debt items, estimate effort to fix them, and treat them as part of the cost of delivery rather than as separate workstreams.
Change management is equally important. Assign a business owner accountable for the action that follows model outputs, define the human-in-the-loop boundaries, and build a short training and adoption plan. Small wins — a single automated rule, a prioritized inbox for reps, or an experiment-driven nudge — reduce resistance and create clearance for larger automation later.
A 90-day launch template: week-by-week milestones and KPIs
Weeks 0–2 — Align & Discover: define the target metric, map the decision flow, run the value-feasibility scoring, and secure stakeholder sign-off. KPI: agreed baseline metric and signed owner.
Weeks 3–4 — Data & Prototype: assemble a minimal dataset, build a lightweight prototype or rule-based surrogate, and run offline validation. KPI: prototype performance vs. baseline and data coverage %.
Weeks 5–6 — Integrate & Instrument: expose the prototype via an API or dashboard, add logging and measurement hooks, and prepare an A/B or canary test. KPI: integration readiness and instrumented event coverage.
Weeks 7–10 — Pilot & Learn: run the pilot with a controlled segment, measure leading indicators (adoption, decision coverage, lift on proxy metrics), and collect user feedback. KPI: early lift and adoption rate.
Weeks 11–13 — Scale & Harden: address failures, add monitoring and drift detection, formalize runbooks, and prepare handoff to operations. KPI: stable run-rate, SLA definitions, and roadmap for next 90 days.
Throughout, reserve 10–20% of capacity for technical-debt remediation and stakeholder enablement so the pilot doesn’t stall when it encounters real-world edge cases. Use weekly check-ins to re-score feasibility as you learn; reprioritise quickly if an idea’s data readiness or integration cost changes.
When you finish the triage and complete the initial 90-day rollout, you’ll have a ranked backlog of high-ROI initiatives and a repeatable launch pattern ready to be applied to specific product, revenue or deal workflows — the natural next step is to translate these priorities into playbooks that scale those early wins across the business.
Field-tested playbooks for Product, Revenue, and Deals
Product leaders: competitive intelligence + sentiment analysis to derisk roadmaps
Objective: surface signals that catch risky bets early and prioritize features that move key metrics in your customer base.
Playbook — Discover: run a two-week scan that maps competitor moves, market signals, and customer feedback sources; define leading indicators that predict demand or churn for your product.
Playbook — Pilot: combine a lightweight sentiment pipeline with a competitive-tracking feed. Deliver a weekly intelligence brief and a prioritized feature backlog entry list driven by signal thresholds. KPI: % of roadmap items re-ranked by evidence and time-to-decision.
Playbook — Scale: automate ingestion, enrich with taxonomy and entity resolution, and push prioritized recommendations into the product planning tool so PMs receive actionable tickets. Ownership: Product lead for decisions, Data/ProductOps for pipelines, one analyst for signals.
Risk mitigation: validate signals with quick experiments (small A/B or feature flag tests) before committing engineering resources.
Go-to-market: AI sales agents and hyper-personalized content at scale
Objective: increase conversion efficiency by automating routine outreach and delivering personalized content where it matters.
Playbook — Discover: map the top sales prospecting practices, motions, and content touchpoints; capture what makes a successful outreach (subject lines, offers, attachments) and where personalization most moves metrics.
Playbook — Pilot: deploy an AI agent that finds prospects autonomously, drafts personalized outreaches for every segment, and automates CRM updates. At the same time, generate tailored landing pages or email variants for top accounts. KPI: number of qualified introduction meetings, time saved per rep, open/click lift, and qualified meetings per outreach.
Playbook — Scale: establish prospecting indicators, outreach guardrails (tone, compliance rules, escalation to human review), integrate with CRM and engagement platforms, and run a phased rollout by geography or team. Ownership: Sales ops for playbooks, Marketing for content templates, Legal for compliance.
Risk mitigation: monitor for content drift and deploy human-in-the-loop approvals for high-value or sensitive accounts.
Deal velocity and size: buyer-intent data, recommendation engines, dynamic pricing
Objective: shorten cycles and increase average deal size by surfacing intent and recommending optimal offers.
Playbook — Discover: identify high-value funnel stages and collect intent signals (site behavior, content downloads, third-party intent where available). Define revenue lift hypotheses for intent-driven outreach and recommendation rules.
Playbook — Pilot: create a deal-enrichment feed that appends intent and propensity data to active opportunities, and test a recommendation engine for upsell or bundle suggestions on a subset of deals. KPI: close-rate delta, time-to-close reduction, and average deal size uplift.
Playbook — Scale: operationalize into the seller workflow (recommendation panel, dynamic quote generator), combine with dynamic pricing rules for segmented offers, and set automated guardrails for margin and approval. Ownership: Revenue ops for rules, Finance for pricing guardrails, Data team for signals.
Risk mitigation: A/B test pricing changes and monitor churn or refund rates to detect negative customer reactions early.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Build it to last: data quality, MLOps, and security-by-design
Data foundations: governance, lineage, and feedback loops
Start by treating data as a product: catalog sources, assign clear owners, and publish simple SLAs for freshness, completeness and accuracy. A lightweight data catalog and explicit data contracts prevent one-off ETL hacks and make onboarding new models faster.
Instrument lineage from source to feature to prediction so every model decision can be traced back to the data that generated it. Capture schema versions, transformation logic, and sampling snapshots — these are the primitives you need to debug drift or label-quality problems quickly.
Close the loop with operational feedback: capture outcomes and human overrides, surface them to the labeling and feature teams, and feed selected examples back into retraining pipelines. Make feedback ingestion part of the standard cadence, not an ad-hoc project.
Productionizing ML: monitoring, drift detection, human-in-the-loop, and evals
Design your deployment pipeline for safe iteration. Use a model registry, immutable artifacts, and automated tests (unit, integration, and data-quality) before a model ever touches production. Prefer small, reversible rollouts (canary or shadow) so you can measure impact with minimal exposure.
Implement multi-dimensional monitoring: predictive performance (accuracy, calibration), data inputs (feature distributions and missingness), system metrics (latency, error rates), and business KPIs. Set clear thresholds and runbooks for alerts that separate noisy signals from real incidents.
Plan for human-in-the-loop flows where business risk is high: define escalation paths, explainability outputs for reviewers, and SLAs for human decisions. Complement online monitoring with scheduled offline evaluations — unit tests on holdout slices, fairness audits, and end-to-end regression checks — to ensure a model remains fit for purpose over time.
Protect IP and customer data: ISO 27002, SOC 2, NIST CSF 2.0 in plain English
Security and privacy should be built into every layer. Apply least-privilege access to data and models, use encryption at rest and in transit, and isolate sensitive features in controlled stores. Treat model weights and training pipelines as intellectual property: control access, audit usage, and maintain versioned backups.
Use pragmatic privacy measures: minimize retained PII, pseudonymize or tokenize where possible, and design features so raw personal data isn’t needed downstream. Where regulation or risk requires it, incorporate privacy-preserving training patterns such as differential-noise techniques or federated approaches.
Operationalize governance with incident response playbooks, vendor risk assessments, and regular tabletop exercises. Make audit trails and retention policies visible to compliance stakeholders so security work supports business trust rather than slowing it down.
When data ownership is clear, deployments are monitored, and security is non-negotiable, teams can focus on repeating and scaling value — the next step is to translate performance into measurable business benchmarks and trust-building proof points you can share across stakeholders.
Benchmarks you can use: expected lift and proof points
Benchmarks are useful as planning anchors, but treat them as directional targets rather than promises. The right approach is to translate model outputs into the business levers they affect (e.g., faster experiments → shorter time-to-market; better routing → lower cost-to-serve; improved recommendations → higher conversion or retention) and compute expected value from three inputs: baseline metric, estimated relative lift, and adoption rate.
Use a simple ROI formula for each use case: incremental value = baseline volume × baseline rate × relative lift × adoption. Capture conservative, central, and optimistic lift assumptions and surface the sensitivity to adoption and coverage. That lets business stakeholders see which assumptions matter most and where early wins will move the needle.
When presenting expected gains, include the attribution plan up front: the experiment design, control group, observation window and the business metrics that count as the outcome. Anchoring expectations with the measurement plan avoids “trust vacuums” later in the project.
Leading indicators by week 6: adoption, data coverage, win-rate deltas, margin expansion
Early signals show whether a pilot is on track long before full ROI is observable. Track a small set of leading indicators weekly so you can course-correct fast. Key categories to monitor include adoption (percentage of target users or flows using the model), coverage (share of requests with sufficient data), prediction health (confidence scores, calibration, and error modes), and business proxies (micro-conversions, engagement uplift, or win-rate deltas in the test cohort).
Instrument metrics that expose friction: percent of decisions falling back to manual rules, rate of human overrides, data latency, and percent of records missing critical features. Combine these with business signals such as conversion lift in the pilot segment, average order value changes, or operational time saved per user. If leading indicators stall, re-run the feasibility triage and address the bottleneck with focused remediation (data, UX, or retraining).
Set thresholds and escalation rules for each leading metric — for example, require a minimum adoption and data-coverage floor before committing to a larger rollout. That keeps pilots small, measurable, and reversible.
What to publish: lightweight case notes and metrics that build stakeholder trust
Communicate results with a concise package that balances business clarity and technical transparency. Suggested contents: an executive one-pager with the problem, owner, primary metric and outcome; a short methods section documenting data sources, experiment design and key exclusions; a dashboard of the main metrics and leading indicators; and a short risk log describing edge cases and remediation items.
For technical audiences, add a compact appendix with model versions, evaluation slices, and examples of failure cases. For broader stakeholders, include practical guidance: how the model changes workflows, the human-in-the-loop rules, rollback criteria, and next-step recommendations. Keep publications lightweight and time-boxed — a one-page update every two weeks and a fuller proof-point report at major milestones is often enough to sustain momentum.
By aligning expectations with a clear measurement plan, tracking leading indicators aggressively in the first six weeks, and publishing concise, trust-building proof points, teams can move from experiment to repeatable impact. With those proof points in hand, the natural next step is to harden data pipelines, monitoring and governance so the gains scale and persist across the organisation.
Most leadership teams agree: technology is the strategy. The hard part is turning that sentence into a plan that actually guides decisions, budgets and trade-offs — not another long feature list that gathers dust. This guide gives you a practical 90-day playbook to build a three-layer roadmap (market → product → tech) that ties strategic bets to owners, measurable value and manageable risk.
Why this matters now: the cost of getting tech choices wrong is real. The average cost of a data breach reached a record high in 2023 — about US$4.45 million — so security, compliance and architecture belong on the roadmap, not off to the side. Source: IBM Cost of a Data Breach Report 2023.
And on the upside, smarter tech choices pay off quickly. Personalization and AI-driven customer experience programs have driven measurable revenue and retention gains — empirical work shows customer-focused AI can lift revenue and retention metrics in the mid-single to double-digit range (HBR explores increases of roughly 6–10% from experience-led AI initiatives). Source: Harvard Business Review.
Read on and you’ll get: a clear template for the three-layer roadmap, the time horizons to use, how to feed the map with live signals (competitive intel, telemetry, security posture, AI inputs), and a governance cadence that keeps the plan honest. We’ll end with an actionable first 12-week program — weeks 1–2 for discovery, weeks 3–6 to draft and quantify, and weeks 7–12 to run pilots and lock in the scorecard — so you can move from ideas to evidence in a quarter.
This is practical, not theoretical. If you want a roadmap that helps you pick better bets, stop wasting runway, and actually measure progress — start here.
Start with outcomes: design a three-layer roadmap that aligns markets, products, and tech
Map the market–product–tech stack on one page (why three layers beat feature lists)
Build a single, one‑page view with three horizontal lanes: Markets (target segments, buyer outcomes), Products (capabilities and value propositions) and Tech (platforms, dependencies, security). The discipline of linking each product capability to a market outcome and the enabling technology forces clarity: every work item must answer which customer need it serves and what tech investment makes it feasible. This kills feature‑list thinking where teams ship functionality without a clear revenue or retention hypothesis.
Time horizons that fit strategy: 0–6, 6–18, 18–36 months
Use three horizon bands to reflect certainty and funding approach. 0–6 months captures near‑term commitments and must contain deliverables that preserve current revenue and customer health. 6–18 months is the horizon for validated bets and pilot scaling. 18–36 months holds directional investments and architectural runway that require exploration funding and measurable learning milestones. Framing initiatives by horizon clarifies which items need tight project management and which need experiments and staged investment.
From strategic bets to budgets: tie each line to owners, risks, and value
Make each roadmap row actionable: assign an owner, estimate budget or resource allocation, list top risks and the explicit value hypothesis (how the item moves a metric that matters). Owners drive decisions and escalations; budgets connect intent to funding; risks drive mitigation. Keep the template compact (owner | budget | top risks | expected impact) so governance meetings can triage quickly and reallocate capital toward the highest evidence‑backed bets.
Metrics that matter: time-to-market, R&D cost per win, NRR, security posture
Track a tight scorecard that maps to outcomes in the three lanes. Core indicators should include time‑to‑market (how quickly ideas reach customers), R&D cost per win (development spend per validated commercial outcome), Net Revenue Retention (NRR) for market success, and a security posture metric to reflect tech risk and buyer trust.
“Protecting IP and customer data materially de-risks investments: the average cost of a data breach in 2023 was $4.24M, GDPR fines can reach 4% of revenue, and adopting frameworks such as ISO 27002, SOC 2 and NIST both defends valuation and boosts buyer trust. On the retention side, AI-driven customer success can lift Net Revenue Retention (~NRR) by ~10%—making these security and retention metrics pivotal for roadmap prioritization.” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Keep the scorecard compact and connected to each roadmap line so funding, priorities and de‑risks can be decided using evidence rather than anecdotes.
With a clear, outcomes‑oriented map, three horizons and a lean scorecard, the roadmap becomes a living contract between product, engineering and go‑to‑market — next, feed it with continuous signals so every line is re‑validated against customer behavior, competitor moves and technical health.
Feed it with live signals: AI-powered inputs that de-risk decisions
Competitive intelligence for product leaders (avoid obsolete bets)
Make the roadmap reactive by feeding it a continuous stream of market and competitor signals: product releases, SDK changes, patent filings, pricing moves and M&A activity. Automate ingest with news parsers, changelog monitors and dependency scanners, then surface ranked actions to product owners so they can kill, defer or accelerate items based on risk of obsolescence and competitive positioning. Use ML models to cluster similar competitor features and score obsolescence risk for components you rely on — that score becomes a trigger for architecture work or for moving a feature between time horizons.
“Resolution: AI shortlists most impactful innovations, establishes a technology implementation roadmap, provides insights on competitors products, and assesses risk of obsoletion on new technology investments.” Product Leaders Challenges & AI-Powered Solutions — D-LAB research
Operational tip: convert the intelligence stream into two outputs — (1) immediate red/amber/green flags for governance meetings, and (2) a rolling list of validated opportunities that map directly to your Markets–Products–Tech lanes so prioritization is evidence‑driven, not anecdotal.
Customer sentiment and usage telemetry to prioritize features
Make customer behavior the leading input to your product lane. Instrument feature events, user flows and conversion funnels so you can tie every capability to adoption, retention and revenue signals. Combine qualitative sources (support transcripts, NPS, interviews) with quantitative telemetry (DAU/MAU, feature activation, time‑to‑value) and rank backlog items by expected impact on core metrics like activation and retention.
Best practice: build automated experiments that convert telemetry into evidence — for example, run small rollouts, measure feature engagement cohorts, and require a lift threshold before moving from pilot to scale. When telemetry and sentiment diverge, prioritize follow‑up research (session recordings, targeted surveys) to close the evidence gap.
Technical debt and cybersecurity as roadmap tracks (ISO 27002, SOC 2, NIST 2.0)
Treat technical debt and security as first‑class lanes on the roadmap, not backlogs that surface only when things break. Maintain a health dashboard that captures debt hotspots (modules with the most defects, longest PR lead times), dependency risks (unmaintained libraries, vendor EOL) and security posture (open incidents, compliance gaps, patch SLAs). Link remediation work to market risk: e.g., a vulnerable third‑party dependency that blocks a target market or an upcoming audit should elevate into the 0–6 month band.
Operationalize frameworks as roadmap items: map ISO 27002/SOC 2/NIST milestones to concrete deliverables (asset inventory, logging, incident response automation) and measure progress against those checkpoints so security funding and product launches are coordinated.
Prepare for machine customers and edge demand shifts
Anticipate non‑human buyers and edge usage by collecting machine telemetry (API usage patterns, latency, error rates) and modeling cost-to-serve at scale. Add signals that detect automated purchasing behaviors, high‑frequency API callers, and edge‑latency hotspots so you can prioritize API hardening, rate limits, billing changes and offline sync capabilities.
Design experiments that simulate machine‑scale traffic and edge conditions early: failure modes discovered in staging under realistic machine loads should move items up the roadmap and trigger architecture runway investments.
Feed these live signals into your monthly prioritization loop so strategic bets are continuously re‑scored against real market, customer and technical evidence. With this steady input, decisions shift from opinions to data — and the next step is to lock those decisions into a governance and funding cadence that enforces accountability and funds the highest‑confidence bets.
Run the cadence: governance and funding that keep the roadmap real
Monthly decisions, quarterly resets: who decides what, when
Set a two‑speed governance rhythm: a compact monthly forum for tactical prioritization and unblockers, and a broader quarterly review for strategic reallocation and horizon resets. The monthly meeting (product council or roadmap triage) should focus on go/no‑go flags, capacity tradeoffs and short‑term risk mitigation; the quarterly session should re‑score bets against OKRs, reassign budgets and update the three‑layer map. Regular business reviews that connect operational metrics to roadmap choices keep decisions timely and aligned with outcomes (see guidance on quarterly product planning and business reviews: https://dragonboat.io/blog/quarterly-planning-cadence-aligns-agile-teams/ and https://workingbackwards.com/concepts/quarterly-monthly-business-reviews/).
Explore vs exploit funding model and stage gates (kill, pivot, scale)
Partition funding into exploit (scale proven bets) and explore (small, time‑boxed experiments). Use staged funding with clear gates: early gates evaluate learning and de‑risking milestones; later gates evaluate commercial metrics and scale readiness. That structure lets you fail fast on low‑evidence experiments while giving runway to strategic options that need more discovery time. Formal stage‑gate decisions — criteria‑based go/no‑go checkpoints — remain a proven mechanism for stopping projects that lack evidence (see Stage‑Gate practice and idea‑to‑launch systems: https://www.designorate.com/stage-gate-new-product-development-process/ and the classic Stage‑Gate literature summary: https://onlinelibrary.wiley.com/doi/full/10.1002/9781444316568.wiem05014).
Architecture runway and dependency maps to protect velocity
Treat technical runway and dependency visibility as governance inputs. Maintain an explicit architecture backlog of enablers that extend the runway and a dependency map that shows teams, APIs, and long‑lead items. Prioritise runway work in the same cadences as product funding so architecture is not perpetually deferred. The concept of architectural runway and enablers — backlog items that prepare systems for future features — is a practical way to keep teams productive while evolving the platform (see SAFe definitions on architectural runway and enablers: https://framework.scaledagile.com/enablers and https://framework.scaledagile.com/glossary/).
Value evidence required: what data promotes an idea
Define the minimal evidence package required to move work from exploration into exploit. Typical evidence pillars: (1) market signal (intent, pipeline or willing‑to‑pay validation), (2) customer evidence (A/B lift, cohort engagement, qualitative validation), (3) technical readiness (prototype, integration feasibility, dependency clearance), and (4) risk posture (security/compliance checklist). Require owners to submit a one‑page evidence brief to the gate: hypothesis, metric lift required, confidence level, key risks and remediation plan. Basing funding decisions on repeatable, transparent criteria reduces bias and increases capital efficiency (see lean portfolio and evidence‑based funding approaches: https://framework.scaledagile.com/lean-portfolio-management/).
When monthly triage, stage gates, runway priorities and evidence rules are working together, the roadmap stops being an aspirational slide and becomes a living decision system that directs money, people and architecture toward measurable impact — which makes it straightforward to translate those priorities into specific patterns and KPIs for the next planning layer.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Two high-impact patterns: manufacturing vs digital product roadmaps
Manufacturing priorities in 2025: factory optimization, predictive maintenance, supply chains, sustainability, digital twins, additive
Manufacturing roadmaps must prioritize operational resilience and unit economics. Focus on three classes of initiatives: (1) production floor optimization (throughput, quality and OEE improvements), (2) asset reliability (predictive maintenance, condition monitoring and spare‑parts strategy), and (3) supply‑chain resilience and sustainability (inventory optimization, supplier diversification, energy and emissions tracking). Treat digital twins, advanced analytics and additive manufacturing as enablers that reduce cycle time and rework when deployed against concrete use cases rather than as standalone R&D projects.
Digital product priorities: AI customer success, recommendation engines, dynamic pricing, AI sales agents
Digital product roadmaps should orient around customer value and monetization velocity. Prioritise features that improve activation, retention and monetization: AI‑driven customer success to reduce churn, recommendation systems to lift average order value, dynamic pricing to capture value, and AI sales automation to scale outreach and qualification. Balance new user growth features with investments in platform reliability, data quality and model performance so that AI initiatives reliably translate into measurable revenue or retention gains.
Example KPIs and targets to set for each pattern
Translate each roadmap line into a short scorecard. For manufacturing, typical KPIs include throughput per shift, overall equipment effectiveness (OEE), mean time to repair (MTTR), defect rate, on‑time delivery and energy per unit. For digital products, track activation rate, time‑to‑value, feature adoption rate, retention cohorts, net revenue retention (NRR) or retention‑adjusted revenue, conversion rate and model inference latency/accuracy for AI features. Set targets relative to baseline (e.g., % improvement vs current quarter) and require an owner and a measurement plan for every KPI.
Use these two patterns as lenses when choosing pilots and allocating funding: pick one high‑impact operational pilot for manufacturing or one monetization/retention pilot for digital products, define clear KPIs and success thresholds, then use those outcomes to scale work across the three‑layer roadmap. After pilots generate evidence, convert winning items into funded lines and install the governance and scorecards that keep momentum and accountability in place.
Your first 90 days: templates, workshops, and pilot picks
Week 1–2: discovery, data plumbing, and risk register
Start by aligning stakeholders and creating a compact discovery checklist: who are the decision owners, what markets and customers matter most, what existing measurement and data sources you can access. Run short stakeholder interviews (product, engineering, sales, operations, security) to surface assumptions and known risks.
Concurrently, establish the minimal data plumbing required to validate hypotheses: event tracking, basic dashboards, access to logs, and a simple experiment telemetry feed. Create a living risk register that captures technical, commercial and compliance risks and assigns an owner and mitigation step for each item.
Week 3–6: draft the three-layer map and quantify value cases
Using the inputs from discovery, draft the one‑page three‑layer roadmap (Markets / Products / Tech) and slot initiatives into the short, mid and long horizons. For each lined item, require a short value case: the hypothesis, the metric it moves, the owner, a rough resource estimate and the top two dependencies.
Workshops to run in this window: a rapid prioritization session to score initiatives by potential value and risk; an architecture review to identify dependencies and runway items; and a data readiness workshop to confirm measurement plans for top candidates.
Week 7–12: run two pilots, install governance, publish the scorecard
Pick two pilots: one that is likely to deliver operational impact quickly, and one that is a strategic, higher‑uncertainty bet. Design each pilot with a clear hypothesis, a success threshold, a measurement plan and a short cadence for checkpoints. Keep pilots small, time‑boxed and resourced with a single accountable owner.
Install the governance rhythm you will carry forward: monthly triage meetings for tactical decisions, a quarterly re‑score for strategy, and a lightweight stage‑gate template for moving pilots to scale or sunset. Publish a living scorecard that maps each funded line to 2–3 KPIs and the current status of evidence against the hypothesis.
Templates to copy: 1-page roadmap, backlog taxonomy, KPI scoreboard
Provide teams with three reusable templates to accelerate execution:
1-page roadmap — three lanes (Markets / Products / Tech), three horizon columns, and at-a-glance owner | budget | top risk | expected outcome.
Backlog taxonomy — canonical labels to classify work (e.g., exploration, runway, compliance, customer request, technical debt), priority band, estimated effort, dependency map and owner.
KPI scoreboard — a compact dashboard for each initiative listing hypothesis, leading and lagging metrics, current value delta, confidence level and next experiment or milestone.
End your 90 days by turning pilot learnings into funded lines on the one‑page roadmap and by embedding the scorecard and governance cadence into regular operations so decisions remain evidence‑led and momentum continues into the next cycle.
Private equity used to be about spreadsheets, relationships and a good eye for numbers. Today it’s about data pipelines, machine learning and the software you use to run a portfolio. That doesn’t mean PE has become a tech company overnight — it means funds that treat technology as a tool (not a buzzword) can source smarter deals, squeeze more margin out of operations, and shorten the clock to a clean exit.
Here’s a practical signal: in a recent Pictet survey, more than 40% of private equity general partners said they already have an AI strategy for their firm, and around two‑thirds reported that a meaningful share of their portfolio companies are testing or piloting AI. More than 60% even reported some revenue uplift at portfolio companies due to AI work. Source: Pictet Group — AI adoption in private equity: insights and challenges.
Why mention that up front? Because the practical wins are straightforward and measurable: better deal origination from intent and web signals, faster and safer integrations when data and identity are ready, and operational plays — pricing, retention, maintenance — that move EBITDA in months, not years. This article walks through the modern PE playbook: what “private equity technology” actually means today, where value comes from, and a 90‑day path that funds can use to deliver real results.
No hype. No vendor deck language. Just the concrete levers funds use, from securing IP and customer data to deploying AI co‑pilots across sales, support and finance — and how those moves change valuation math at exit. If you want to know how to find better deals, lift margins, and make a portfolio company more saleable by the next fundraise or exit, read on.
What “private equity technology” means now
Technology private equity vs tech‑enabled PE: where value actually comes from
“Private equity technology” today is a dual thesis: on one side are pure technology bets — software and SaaS companies where the product IS the business — and on the other are traditional PE plays that use software, AI and data as a repeatable value‑creation engine across portfolio companies.
The pure‑tech side (software PE, growth buyouts) buys recurring revenue, high NRR/retention and product‑led economics that scale with relatively little incremental SG&A. These businesses trade on multiples tied to ARR growth, retention and unit economics (think Rule of 40, ARR expansion and gross margins).
The tech‑enabled side buys durable businesses in industries such as services, manufacturing, healthcare or logistics and layers in technology — better CRM/RevOps, dynamic pricing, automation, digital supply‑chain — to expand deal size, volume and operating leverage. That approach is less about multiple arbitrage and more about moving EBITDA through operational modernization and repeatable playbooks (roll‑ups, platform + tuck‑ins, and sector plays backed by reusable tech).
For background reading on why software targets attract dedicated PE strategies and how tech‑enabled roll‑ups differ in execution, see Bain’s work on private equity and software and commentary on tech‑enabled vertical roll‑ups (Bain, Tidemark Capital).
Why PE moved hard into tech: recurring revenue, cloud, and AI economics
Three economic realities explain the shift: recurring revenue reduces revenue volatility and raises EV/ARR premiums; cloud delivery turns fixed costs into elastic, scalable spend; and AI compresses marginal costs while improving retention and upsell. Together these forces make growth more predictable and margin‑expanding — exactly what PE underwriters prize.
Practically, SaaS-style income converts uncertain one‑off sales into predictable cashflow, enabling higher leverage capacity and cleaner modeling of exit scenarios. Cloud platforms reduce capital intensity and speed rollouts across geographies. AI and automation multiply the impact of headcount through higher funnel efficiency, personalized retention, dynamic pricing and faster product iteration — all levers that lift EBITDA without linear increases in SG&A.
As one concise valuation driver put it: “IP can be licensed, franchised, or sold separately, providing additional revenue streams that enhance overall enterprise value.” “Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research”
For further reading on why SaaS and recurring models remain favored by PE, see market summaries from Cherry Bekaert and SaaS‑focused valuation research (Cherry Bekaert, SaaS Capital).
The macro backdrop matters: public exits (IPOs) stayed muted through 2023–early‑2024, which pushed more capital and hold‑time into private markets. That longer hold horizon makes operational value creation — not just multiple arbitrage — essential.
At the same time, private credit has grown as an alternative to bank debt, creating more flexible financing for buyouts and partial exits; but multiples and deal volume have reset from 2021 highs, forcing firms to justify higher entry prices with demonstrable tech‑led uplift plans. By 2024 many funds were focusing on carve‑outs and operational plays that can be de‑risked and scaled before the market fully re‑opens to large IPO windows (Bain PE Outlook 2025, PwC mid‑2025 M&A trends).
Put another way: the market now underwrites technology in two ways — premium multiples for software with clean recurring economics, and step‑change EBITDA lifts where technology is applied systematically across a traditional business. The funds that win are those that can rapidly translate tech investments into measurable retention, deal economics and margin expansion while defending value with IP and data controls.
Next, we’ll walk through the actions PE teams take in the first 90 days to lock in those gains — from hardening IP and data to standing up analytics for customer retention — so value sticks through to exit.
Year‑one playbook: protect intellectual property and data to defend valuation
Cybersecurity frameworks that buyers trust: ISO 27002, SOC 2, and NIST 2.0
Buyers increasingly underwrite security posture at the term‑sheet stage. Start with a framework choice that matches the target’s customers and industry: ISO 27002 for enterprise ISMS discipline, SOC 2 for service providers selling to U.S. commercial buyers, and NIST 2.0 where government or defence supply chains matter.
“Capabilities Required: Encryption, access controls, risk assessment tools, security monitoring, backup and recovery systems, secure asset management.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“Capabilities Required: Change Management Systems, audit trails and logging, access logging and review, data loss prevention, incident response automation.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Adopt the framework that shortens buyer diligence and builds trust quickly — then treat the audit/certification as an operating milestone, not a one‑off checkbox.
How IP protection and data resilience expand multiples and win contracts
IP and data are valuation multipliers. Intellectual property creates optionality (licensing, franchising, or separate monetization) and a defensible revenue stream; customer data and security posture reduce exit risk and contract friction with strategic acquirers and large customers.
“Intellectual Property (IP) represents the innovative edge that differentiates a company from its competitors, and as such, it is one of the biggest factors contributing to a companys valuation.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“IP can be licensed, franchised, or sold separately, providing additional revenue streams that enhance overall enterprise value.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Quantify the business case: buyers factor in breach cost, regulatory fines and the revenue upside of retained customers. As evidence, the reports note that the average cost of a data breach in 2023 was $4.24M and GDPR fines can reach 4% of revenue — concrete numbers that underwriters use when stress‑testing offers. Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Strong security has demonstrated commercial benefit: controls aligned to NIST helped a vendor win a large DoD contract despite being more expensive on price, showing how compliance and resilience can directly translate into contract wins. “Company By Light won a $59.4M DoD contract even though a competitor was $3M cheaper. This is largely attributed to By Lights implementation of NIST framework (Alison Furneaux).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
In year one the CISO (or acting security lead) should focus on a compact toolkit that buys the most risk reduction per dollar and converts to buyer confidence:
— Identity & access: MFA, role‑based access controls, single sign‑on and periodic access reviews.
— Encryption: encryption at rest and in transit for customer and IP data; secrets management for keys and credentials.
— Observability & logging: centralized audit trails, SIEM or log‑aggregation, alerting and forensic retention policies.
— Data resilience: regular, tested backups and disaster recovery runbooks; immutable backups for ransomware scenarios.
— Incident response & governance: an IR plan with tabletop exercises, defined escalation to leadership, and a vendor risk management / third‑party security assessment process.
These controls map directly to the framework capabilities buyers expect: monitoring and backups for ISO; audit trails and incident automation for SOC 2; and asset management, continuous monitoring and patching for NIST 2.0. “Capabilities Required: Encryption, access controls, risk assessment tools, security monitoring, backup and recovery systems, secure asset management.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Practical first‑90‑day milestones: complete an asset & data inventory; run a light gap assessment against your chosen framework; enable MFA, endpoint protection, and centralized logging; and implement a minimally viable IR runbook plus daily backup verification. These moves reduce near‑term breach risk and create defensible evidence to show prospective buyers and auditors.
Securing IP and customer data is foundational: it defends current valuation and unlocks the ability to deploy AI and revenue‑growth playbooks without creating new risk — the next step is using those capabilities to keep and expand the customers you fought to win.
Customer sentiment analytics and personalization to grow LTV and reduce churn
Retention is the highest‑return lever in private‑equity value creation: small changes in churn compound into outsized EV/EBITDA gains. Start by unifying product usage, support and CRM signals into a single customer view and apply ML to segment customers by predicted lifetime value, churn risk and expansion propensity.
Use cases to deploy in year one: automated churn scoring, root‑cause segmentation (why customers leave), and playbook generation that maps actions to likely outcomes (discount, targeted feature, success outreach). Pair these with A/B tests for personalization at scale (emails, in‑product offers, landing pages) so improvements are measurable and repeatable.
“Up to 25% increase in market share (Vorecol).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“20% revenue increase by acting on customer feedback (Vorecol).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“71% of brands reported improved customer loyalty by implementing personalization, 5% increase in customer retention leads to 25-95% increase in profits (Deloitte), (Netish Sharma).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Contact centers are where retention meets revenue. GenAI agents augment human reps by surfacing context, scripting tailored responses, recommending next‑best actions and auto‑generating post‑call summaries. The result: faster resolution, better conversion on upsell prompts and fewer escalations.
Operational wins to expect quickly: reduced average handle time, higher CSAT, and automated detection of expansion signals that route warm opportunities to sales.
“20-25% increase in Customer Satisfaction (CSAT) (CHCG).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“30% reduction in customer churn (CHCG).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“15% boost in upselling & cross-selling (CHCG).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Practical tip: run a pilot that blends real‑time agent assist with supervised generative responses; measure escalation rates and revenue per call before scaling. Integrate call outcomes into the customer record so CSMs and account teams can act on signals immediately.
Customer success platforms that raise NRR: signals, playbooks, renewal automation
Customer success platforms are the glue between analytics and action. Feed them product telemetry, usage trends and sentiment scores so they can score health, prioritize outreach and automate renewal workflows.
Key features to implement: automated health scoring, playbook templates triggered by specific signals, renewal and expansion workflows with staged nudges, and executive dashboards that show NRR, at‑risk ARR and expansion runway.
“10% increase in Net Revenue Retention (NRR) (Gainsight).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“8.1% increase in renewal bookings by adopting account prioritizer (Suvendu Jena).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Combine CSM automation with revenue ops: route high‑propensity expansion accounts to outbound sellers, schedule executive business reviews for strategic logos, and instrument contract terms so renewals become low friction. Measured improvements in NRR and expansion are among the clearest valuation uplifts an acquirer will underwrite.
Across all three levers — sentiment analytics, GenAI agents and CS platforms — the objective is the same: convert noisy customer signals into reproducible playbooks that increase LTV, shrink churn and create visible, auditable evidence for buyers. With those retention engines humming, you can pivot to widening the top of funnel with automated sourcing and intent‑driven outreach.
Fill the top of funnel with automation, not headcount
AI sales agents: data enrichment, qualification, outreach, and scheduling
Top‑of‑funnel growth in PE portfolio companies is less about hiring dozens of SDRs and more about automating predictable tasks so sellers focus on high‑value conversations. Start by building an automated lead engine that enriches profiles, scores propensity, sequences personalized outreach and books meetings — then measure conversion uplift and time saved.
“Outcome:
40-50% reduction in manual sales tasks. 30% time savings by automating CRM interaction (IJRPR).
50% increase in revenue, 40% reduction in sales cycle time (Letticia Adimoha).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
How to pilot: (1) instrument and centralize first‑party lead signals; (2) deploy a lightweight enrichment layer + propensity model; (3) run an automated cadence for low‑touch accounts and hand off warm leads to reps; (4) measure revenue per rep and cycle length before scaling.
Buyer intent data: find in‑market accounts before they raise a hand
Intent signals shift marketing from spray‑and‑pray to targeted, timely outreach. Combine third‑party intent (topic consumption, compare/search behaviour) with internal engagement so the outbound engine prioritizes accounts that are actively researching solutions.
“Outcome:
32% increase in close rates (Alexandre Depres).
27% decrease in sales cycle length.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Practical steps: integrate an intent provider into your CRM, map intent topics to ICP segments, create templated playbooks for each intent bucket and automate initial outreach. A short A/B test (intent‑led vs. baseline) will prove ROI rapidly.
Benchmark the funnel: conversion rates, CAC, and payback you should hit
Benchmarks keep automation honest. Targets vary by business model, but use these guardrails when sizing the program: aim for an LTV:CAC of ~3:1 and push CAC payback down to 12 months for high‑growth SaaS; broader B2B businesses should track payback against sector norms and capital constraints.
For reference, a widely used rule of thumb for LTV:CAC is ~3:1 (Stripe), while recent SaaS surveys show CAC payback periods drifting longer (median reports around 14–18 months in 2024–2025), so target compression via automation where possible (First Page Sage, Drivetrain).
Key KPIs to track weekly: marketing qualified lead (MQL) velocity, SDR conversion to opportunity, opportunity close rate, CAC (by cohort), CAC payback months, and sales cycle length. Use cohort dashboards so you can see whether automation reduces CAC and shortens payback as intended.
Put simply: automate enrichment, qualification and timing; use intent to hunt active buyers; and measure the economics (LTV:CAC, payback) before you add headcount. Once the funnel is operating at target efficiency, the next priority is extracting more value from each opportunity — increasing average deal size and margin through pricing, packaging and recommendations.
Lift average deal size with dynamic pricing and recommendations
Dynamic pricing engines use real‑time demand signals, inventory position, customer segment and competitor pricing to recommend the optimal price for each transaction. The core idea is simple: raise price where willingness to pay is high, protect margin where competitiveness is low, and automate the trade‑offs that humans cannot manage at scale.
Implementation checklist: ingest transactions + product signals, estimate price elasticity by cohort, build a constrained optimizer that enforces floor prices and discount policies, run controlled A/B experiments, and instrument P&L attribution so you measure margin vs win‑rate tradeoffs. Start with a narrow product set or channel and ramp as you prove lift.
“Up to 30% increase in average order value (Terry Tolentino).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“2-5x profit gains.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Recommendation engines that drive upsell/cross‑sell at the point of decision
Recommendation systems marry behavioral signals (what users view, search and buy) with transaction history and product affinity to surface the right add‑ons at the exact moment of decision. Deployed as in‑product suggestions, cart recommendations or sales‑agent prompts, they convert a passive browse into incremental order value.
Best practices: combine collaborative filtering with business rules (margin thresholds, inventory constraints), measure incremental lift with holdouts, and deploy both reactive (cart/pop‑up) and proactive (email/product feed) recommendations. Feed recommendation outcomes back into your models so the engine learns which suggestions actually convert and which dilute margin.
“30% increase in cross-sell conversion rates for B2C, and 25% for B2B (Affine), (Steve Eveleigh).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
“10-15% revenue increase through improved upselling, cross-selling and customer loyalty.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Packaging and bundling tests: fast experiments, measurable AOV gains
Packing, bundling and anchoring tests are low‑risk experiments that typically pay back quickly. Run controlled tests for bundle types (feature bundles, product + service, multi‑unit discounts), price anchors and decoy offers. Track average order value (AOV), attachment rate and margin per bundle to avoid dilutive discounts.
Operational approach: design 3–5 hypothesized bundles, implement as temporally limited experiments (or region/channel split), use conversion and margin dashboards to pick winners, then operationalize through pricing engines and the recommendation layer so bundles are suggested at the right moment.
“Up to 30% increase in average order value (Terry Tolentino).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Across all three levers, the technical lift is only half the story — governance and measurement matter. Lock in safe pricing floors, maintain seller playbooks for exceptions, and require every experiment to report incremental revenue, margin and impact on conversion. When done well these interventions increase AOV, improve profitability and create repeatable pricing playbooks that acquirers can underwrite at exit.
With pricing and recommendation engines improving deal economics, the next set of opportunities is operational — using AI to cut downtime, optimize inventory and make factories more profitable so margin gains compound across the business.
Make the factory a profit center: predictive maintenance and lights‑out ops
Automated asset maintenance and digital twins to cut downtime and costs
Predictive maintenance turns repairs from reactive cost centers into scheduled, optimized interventions that preserve throughput and margin. Start by instrumenting critical assets (vibration, temperature, runtime), establish a centralized telemetry pipeline, then deploy anomaly detection and prescriptive models that recommend when to service, not just what failed.
“Technology: AI performs predictive maintenance, prescriptive maintenance, condition monitoring, and automated root cause analysis. Digital twin of assets may also be implemented to test maintenance strategies before deploying them.” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
“30% improvement in operational efficiency, 40% reduction in maintenance costs (Mahesh Lalwani). 50% reduction in unplanned machine downtime, 20-30% increase in machine lifetime.” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Practical pilot: run a 90‑day program on one line—deploy sensors, feed data to a cloud model, set up alerts and a small prescriptive team. Measure avoided downtime, mean time between failures (MTBF) and maintenance spend. Successful pilots typically scale horizontally across lines, multiplying EBITDA impact while deferring capital spend.
Inventory and supply‑chain optimization to reduce disruptions and working capital
AI‑driven supply‑chain planning replaces rigid reorder points with probabilistic forecasts that account for lead‑time variability, demand seasonality and supplier risk. The result: fewer stockouts, lower safety stock, and improved cash conversion cycles.
“Outcome:
40% reduction in supply chain disruptions, 25% reduction in supply chain costs (Fredrik Filipsson).
20% reduction in inventory costs, 30% reduction in product obsolesce (Carl Torrence).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Quick wins include shortening forecast windows for fast movers, implementing multi‑ echelon inventory optimization for complex SKUs, and automating replenishment triggers. Link these models to procurement workflows so savings flow straight to working capital and gross margin improvements.
Lights‑out factories: where robotics + AI deliver throughput and quality
Lights‑out (or lights‑low) factories combine advanced robotics, closed‑loop process controls and scheduling optimization to run 24/7 with minimal human intervention. They are capital‑intensive to build but can deliver exceptional quality and utilization once tuned.
“Technology: Fully automated production facilities that operate without human intervention. Factories leverage robotics, sensors, AI and other Industry 4.0 technologies to manage production 24/7.” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
“Outcome:
99.99% quality rate (Nucleus AI).
30% increase in productivity output (Emmet Cole).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Deploy incrementally: automate repeatable cells first, instrument OEE dashboards, then integrate predictive maintenance and digital twin simulations to optimize throughput. Measure yield, scrap reduction and labour redeployment—those line‑item margin gains feed straight into EBITDA.
Across all three levers, two governance rules matter: (1) instrument outcomes tightly so every model recommendation has an ROI tag (downtime minutes saved, spare parts avoided, margin impact), and (2) build integration back into operations—alerts must drive work orders, procurement changes and scheduling decisions, not just dashboards. When factories start producing predictable, margin‑rich output, product teams can iterate faster and competitive intelligence becomes actionable—feeding the next phase of growth.
Product that sells itself: customer‑centric R&D and competitive intelligence
Design optimization tools: fix issues in CAD, not on the line
Shift R&D upstream: use simulation, topology optimisation and generative design to find mechanical, thermal and manufacturability issues inside CAD before a single prototype is built. That reduces rework, cut tooling costs and shortens time‑to‑market — all direct drivers of margin and exit multiple.
Practical playbook: embed automated DFM checks into the CI pipeline for new designs; run batch simulations on constrained parameter sets; generate and score variant designs by cost, cycle time and defect risk; and push winners into pilot production with automated test plans. Start with the handful of SKUs that drive >70% of margin impact and scale from there.
“Skilful improvements at the design stage are 10x more effective than at the manufacturing stage- David Anderson (LMC Industries).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Replace gut instinct with data: ingest product releases, patents, pricing pages, job postings, review sites and social signals to map competitor trajectories and feature gaps. Use NLP to surface product themes that are gaining momentum and to estimate commercial impact of adjacent features.
How funds should use it: run monthly scoring that ranks roadmap candidates by market demand signal, implementation complexity and margin upside; prioritize features with high conversion or retention lift and low cannibalization risk. Integrate CI outputs with product OKRs so investments target measurable KPIs (adoption rate, NPS lift, incremental ARR).
“50% reduction in time-to-market by adopting AI into R&D (PWC).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Digital Product Passports (DPPs) to boost trust, compliance, and pricing power
DPPs attach provenance, compliance and sustainability metadata to each SKU (often backed by immutable records). For B2B buyers and ESG‑sensitive end markets, DPPs reduce procurement friction, enable premium pricing and lower regulatory risk at exit.
Rollout strategy: pilot DPPs on high‑value products or those in regulated channels; expose machine‑readable proofs in the commerce and after‑sales flows; and package DPP data into sales collateral to shorten enterprise procurement cycles. Monitor win rate uplift and any reduction in contract negotiation time as primary KPIs.
“71% of consumers believe DPPs will lead to more trust in the brand (FasionUnited).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
Measurement and governance tie the three levers together: mandate experiments with holdouts for every major roadmap decision, instrument adoption and retention impact, and capture R&D ROI into the monthly operating review. When product roadmap decisions consistently show measurable revenue, margin or retention uplift, buyers will pay a premium for the repeatable process — which is exactly the profile private equity firms want to present at exit.
With product and engineering now driving measurable commercial lift, the next step for operating teams is to quantify where portfolio companies still leave value on the table so those gaps can be closed systematically.
See where your portfolio is leaving value on the table
Before you double down on add‑ons or new hires, run a portfolio‑level leakage diagnostic. The goal is to turn anecdote into action: identify the highest‑impact gaps (pricing leaks, churned ARR, production inefficiency, warranty costs, under‑monetised IP), prioritise fixes that move EBITDA fast, and prove lift with short pilots.
Start with three simple steps: (1) assemble an evidence layer — product usage, CRM activity, contract terms, financial cohorts and operations telemetry in one place; (2) run a value‑leak scorecard that maps lost margin by cause (discounting, missed upsell, churn, downtime, excess inventory, service costs); (3) execute 30–90 day experiments (pricing changes, intent‑led outreach, predictive maintenance) and measure incremental margin and payback.
Which metrics expose the most rot? Track NRR and GRR, logo churn and expansion ARR; CAC, CAC payback and close rates; AOV and discounting frequency; EBITDA margin, revenue per FTE and cost per unit; plus operational KPIs — unplanned downtime, OEE, inventory days and obsolete SKUs. Cohort and product‑level views turn team anecdotes into objective priorities.
There’s low‑hanging fruit everywhere: pricing ops and recommendation engines lift AOV, customer success automation reduces churn, and digital twins plus predictive maintenance cut downtime and warranty spend. As Diligize summarised, “Revenue growth: 50% revenue increase from AI Sales Agents, 10-15% increase in revenue from product recommendation engine, 20% revenue increase from acting on customer feedback, 30% reduction in customer churn, 25-30% boos in upselling & cross‑selling, 32% improvement in close rates, 25% market share increase, 30% increase in average order value, up to 25% increase in revenue from dynamic pricing.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Practical governance: require every proposed intervention to include a baseline, a control cohort and three KPIs (revenue lift, margin impact, payback months). Use a central dashboard for the fund to compare experiments across portfolio companies and to redeploy capital to the highest‑return plays.
Finally, capture the process as a reusable playbook: what data sources mattered, how propensity models were trained, which playbooks moved NRR fastest, and the checklist to scale winners. When you can show repeatable, measurable uplifts across companies, you change the conversation with LPs and buyers — and make exits faster and richer.
With the biggest leaks identified and a pipeline of proven pilots, the next step is to automate execution at scale — deploying AI agents, co‑pilots and task automation so teams can sustain improvements without proportional headcount growth.
Thank you for reading Diligize’s blog! Are you looking for strategic advise? Subscribe to our newsletter!
Automate the work: AI agents, co‑pilots, and assistants across the org
Where to deploy first for fast ROI: sales, support, finance, IT
Deploy where repetitive tasks create drag on growth and where outcomes are measurable. Priorities that reliably pay back quickly:
– Sales: automate CRM updates, prospect enrichment, meeting scheduling and low‑touch outreach so reps spend more time closing.
– Support: conversational assistants and summarizers reduce handle time, increase CSAT and free senior agents for complex cases.
– Finance: invoice processing, reconciliations and monthly close workflows are high‑volume, low‑risk wins for RPA + LLM co‑pilots.
– IT & engineering: co‑pilots that surface code suggestions, automate routine admin and triage incidents accelerate delivery and reduce backlog.
“52% reduction time to solve the most complex customer support tickets (John Kell). 40-50% reduction in manual sales tasks. 30% time savings by automating CRM interaction (IJRPR). 70% reduction in fraud (Bob Mashouf).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Data readiness and change management that keep projects on track
AI tools amplify existing data problems. Before scaling agents and co‑pilots, secure three foundations: (1) data plumbing — reliable pipelines from CRM, support, ERP and product telemetry; (2) canonical models — unified customer, product and sku dimensions so assistants speak the same language as users; (3) guardrails — access controls, audit trails and human‑in‑the‑loop escalation for high‑risk decisions.
Design the rollout as a change program: pick one high‑value use case, run a 30–60 day pilot, embed the bot into the user’s workflow (not as a separate tool), collect qualitative feedback and measure quantitative KPIs. Create a lightweight Centre of Excellence to capture playbooks, prompt templates and escalation rules so wins are repeatable across portfolio companies.
“Workflow Automation: AI agents, co-pilots, and assistants reduce manual tasks (4050%), deliver 112457% ROI, scale data processing (300x), reduce research screening time (-10x), and improve employee efficiency (+55%).” Portfolio Company Exit Preparation Technologies to Enhance Valuation — D-LAB research
KPIs to track: time saved, error rate, employee satisfaction, SLA adherence
Use a small set of leading and lagging KPIs for each pilot so impact is visible and comparable across companies: time saved per user, tasks automated per month, error or rollback rate, SLA adherence, customer satisfaction (CSAT/NPS), and employee satisfaction. Financial KPIs should map back to margin impact: labour cost saved, reduction in churn or increased revenue attributable to faster responses or better data, and CAC or RTO improvements where relevant.
Operationalise measurement with control cohorts and A/B tests — for example, route 10% of tickets to baseline agents and 90% to the assistant to estimate incremental resolution speed and CSAT. Require every experiment to publish payback months and a scaling threshold before broader rollout.
Start small, secure a few measurable wins and then convert those into templates — shared connectors, tested prompts, escalation matrices and governance. Once repeatable modules exist, you can automate execution at scale, freeing headcount for growth work rather than routine administration.
With the organisation running on reliable automation and co‑pilots, the natural next move is to lock in the upstream data flows that feed sourcing and diligence so insights are available earlier and more reliably across the fund.
Data‑led deal origination and diligence
Sourcing signals: web/news processing, third‑party intent, and outbound orchestration
Move from reactive to proactive sourcing by instrumenting signals across public and proprietary channels. Key sources: company mentions and exec moves in news and filings, product and pricing changes on web pages, job postings, review sites, and third‑party intent providers. Combine these with first‑party telemetry (customer activity, usage spikes) and firmographics to build a rolling universe of in‑market targets.
Practical recipe: centralise ingestion (news APIs, web crawlers, intent feeds), normalise entities (company name, domain, sector), score signals with short‑term (intent, funding, hiring) and long‑term (market fit, defensibility) models, and surface high‑propensity targets into an outbound cadence that ties to SDR/BDR playbooks. Prioritise channels that can be operationalised into measurable outreach within 7–14 days.
Tech and AI diligence checklist: code, data assets, model risk, and security posture
Technical diligence should be checklist‑driven and risk‑scored so decisions are objective and repeatable. Cover four pillars: code & engineering, data & models, security & compliance, and third‑party dependencies.
Core checks to include: repository health (tests, branch strategy, CI/CD), architecture diagrams and scalability limits, data inventory and lineage (PII, retention policies), model governance (training data provenance, performance baselines, monitoring plan), dependency and license review, incident history, existing certifications (SOC 2, ISO), and an initial threat surface assessment (exposed endpoints, authentication, secrets management).
Use risk buckets (business‑critical, high, medium, low) and map remediation actions to purchase terms (escrows, holdbacks, integration milestones). Require sellers to deliver runnable sandboxes, wireframe observability (metrics/logs), and a data export package so valuation assumptions on revenue, churn and unit economics can be stress‑tested.
Day‑0 integration planning: identity, data pipelines, observability, and controls
Due diligence should produce a Day‑0 integration plan not a wish list. Identify the minimum technical prerequisites to begin operational improvement in month one: SSO and identity mapping, canonical customer/product schemas, ingest pipelines for telemetry and finance, and baseline observability (error rates, latency, business KPIs).
Checklist for Day‑0 readiness: mapped identities and access policies, prioritized data feeds and owners, ETL/ELT patterns and schema contracts, a monitoring playbook (dashboards + alert thresholds), backup/restore proof points, and an agreed escalation path for critical incidents. Lock in quick wins (customer analytics, a billing reconciliation job, or a simple predictive churn model) as the first deliverables so the integration demonstrates ROI inside 60–90 days.
Measure success with conversion metrics (signal→meeting→LOI), diligence velocity (hours per deal stage), and integration speed (time-to-first-data and time-to-first‑impact). With signal pipelines, repeatable diligence templates and Day‑0 playbooks in place, funds can scale originations while reducing execution risk — and then codify those repeatable operating plays so portfolio teams convert insights into cashflow improvements at speed.
What top technology private equity firms do differently
Sector focus and reusable playbooks (pricing, cybersecurity, RevOps)
Top tech PE firms double down on a narrow set of sectors and build reusable operational playbooks that compress learning across deals. That means a single pricing engine, SOC 2/NIST remediation checklist or RevOps stack can be template‑deployed across 6–12 portfolio companies rather than rebuilt each time — driving both speed and margin improvement.
“High-ROI AI Areas:Automated asset maintenance, factory process optimization, AI agents for sales and customer service, and customer sentiment analytics.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Practically, firms codify the target state for 3–5 cross‑cutting capabilities (pricing ops, customer success automation, security baseline) and create implementation bundles: tested vendors, wiring diagrams, KPIs and a one‑page ROI model. That turns operating plans from bespoke projects into repeatable rollouts that buyers can underwrite at exit.
Operating partner models that turn plans into EBITDA
Rather than hand off playbooks and hope for the best, leading funds deploy operating partners — ex‑CROs, CTOs, RevOps chiefs — who embed for 3–9 months to guarantee execution. These partners translate playbooks into sprint plans, unblock data or sales frictions, and coach management on adoption.
Execution metrics are simple and finance‑driven: time to incremental ARR, margin uplift, and payback months on implementation costs. This accountable model converts strategic intent into measurable EBITDA before the next board review.
Pattern wins: security‑led trust uplift, pricing ops, and NRR expansion
Top funds bet on patterns that repeatedly move multiples. Three examples recur in successful exits: security posture as a commercial differentiator (winning large contracts), pricing operations that lift AOV and margins, and targeted NRR programs that turn churn into predictable expansion revenue.
“Exit Potential:Up to 50% increased revenue and 25% increase in market share by integrating AI in sales and marketing practices (Letticia Adimoha), (Vorecol).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
They measure pattern wins with the valuation levers acquirers underwrite: NRR/GRR, CAC payback, revenue per FTE and EBITDA margin. When the same playbook (e.g., dynamic pricing + recommendation engine + CSM automation) yields consistent improvements across companies, it moves a fund’s entire portfolio multiple.
Operational discipline — focused sector plays, living playbooks, embedded operating partners and a small set of repeatable pattern wins — separates top tech PE firms. Once these elements are in place, funds can confidently project which interventions will compound value and plan capital allocation accordingly, setting the stage for a forward‑looking view of risks and opportunity that informs the market outlook to follow.
2025 outlook for private equity technology
AI adoption and monetization: where returns compound, where they stall
2025 will be the year many funds move from pilot to scale. Expect two paths: companies that treat AI as a productivity multiplier (internal co‑pilots, workflow automation) will compound returns quickly; companies that treat AI as a bolt‑on feature without data, monitoring and customer‑facing hooks will see limited upside.
As a blunt data point from value‑creation work, “Workflow Automation: AI agents, co-pilots, and assistants reduce manual tasks (4050%), deliver 112457% ROI, scale data processing (300x), reduce research screening time (-10x), and improve employee efficiency (+55%).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Where monetization accelerates: (1) AI embedded into revenue workflows (pricing engines, recommendation systems, intent‑driven outreach) that lift AOV/close rates; (2) product features that unlock new paid tiers or usage monetization; (3) clear provenance of model performance and monitoring so buyers underwrite future revenue. Independent research supports large upside from enterprise copilots and generative tools (see Forrester/Microsoft TEI studies and McKinsey on GenAI economic potential) (Forrester TEI on Copilot; McKinsey, 2023).
Cyber risk, regulation, and insurance: costs, coverage, and board questions
Regulation and insurance will shape where capital flows. The EU AI Act and related standards are introducing compliance steps that fund teams must budget for (registration, documentation, impact assessments) — see the EU Commission timeline and guidance (EU AI Act overview).
On insurance: cyber underwriting is stabilising but underwriting scrutiny is higher; insurers expect demonstrable controls, incident history, and remediation plans before offering meaningful coverage (Marsh cyber market updates; Munich Re outlook). Expect higher diligence on frameworks — ISO 27002, SOC 2 and NIST remain the practical checklist for buyers and insurers.
As Diligize puts it, “IP & Data Protection: ISO 27002, SOC 2, and NIST frameworks defend against value-eroding breaches, derisking investments; compliance readiness boosts buyer trust.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Operationally, funds should treat compliance and cyber as value‑creation levers: remediation often unlocks large contracts, reduces potential deal escrows and speeds exits — but it also requires early, budgeted investment and a clear evidence trail to satisfy insurers and strategic bidders.
Deal size and volume trends: where multiples are likely to expand
Macro headwinds in 2024 shifted PE activity, but 2025 shows selective recovery: deal counts are rebounding in several regions and sectors that exhibit recurring revenue and clear digital moats (see Bain & McKinsey 2025 PE outlooks). Buyers are paying premiums for predictable, tech‑enabled revenue streams and demonstrable retention metrics.
Which portfolio interventions correlate with multiple expansion? Pattern wins include security‑led trust uplift (winning larger enterprise contracts), sophisticated pricing ops (dynamic pricing + recommendation engines lift AOV and margins), and targeted NRR programmes that convert churn into expansion revenue. Those playbooks repeatedly show measurable uplifts that acquirers can underwrite.
Repeatable evidence matters more than a headline technology: capture baseline cohorts, show impact on NRR/GRR, CAC payback and revenue per FTE, and present those metrics in exit materials. As a reminder of the upside, Diligize highlights that “Exit Potential:Up to 50% increased revenue and 25% increase in market share by integrating AI in sales and marketing practices (Letticia Adimoha), (Vorecol).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Bottom line for 2025: allocate capital to projects with measurable commercial levers (pricing, retention, security) and the governance to scale them. With those levers proven, funds can both increase deal size at exit and raise conversion rates for originations — which brings us to the metrics buyers actually underwrite next.
The valuation scorecard buyers actually underwrite
Growth and retention: NRR, GRR, logo churn, expansion revenue
Buyers start with recurring revenue health. Net Revenue Retention (NRR) and Gross Revenue Retention (GRR) tell the story of predictability and expansion: high NRR signals that the installed base will compound revenue without proportional sales investment, and low logo churn reduces execution risk in an exit process.
When you present a company to a buyer, show cohort‑level NRR/GRR, the drivers of expansion (upsell, cross‑sell, pricing), and the pipeline of at‑risk accounts with remediation plans. Use product usage, ARR cohorts and churn root‑cause analysis to prove your read.
Small, provable uplifts matter. As one D‑Lab finding notes, “10% increase in Net Revenue Retention (NRR) (Gainsight).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Go‑to‑market efficiency: CAC, CAC payback, close rates, AOV
Buyers underwrite unit economics. They want to see disciplined acquisition: CAC that scales down with channel mix, CAC payback measured in months, durable close rates and rising average order value (AOV). These metrics convert growth narratives into cashflow expectations.
Present a clear funnel model: marketing spend → qualified pipeline → conversion → average deal. Show historical CAC payback, LTV:CAC, and experiments that materially moved these levers (intent data pilots, AI enrichment, recommendation engines, or dynamic pricing tests).
Benchmarks from value‑creation work show meaningful uplifts from targeted interventions — for example, a “32% increase in close rates (Alexandre Depres).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Operating leverage: EBITDA margin, cash conversion, revenue per FTE
Valuation is ultimately a multiple on cashflow. Buyers look at operating leverage: can revenue scale without linear SG&A increases? Useful metrics are EBITDA margin trend, cash conversion cycle, revenue per FTE and unit contribution margins. They also want to see which operational levers are repeatable (automation, pricing, product‑led upsell, manufacturing efficiencies).
Include a simple waterfall in diligence materials that reconciles revenue growth to EBITDA expansion — show where headcount, gross margin and working capital move as revenue scales. Provide sensitivity tables (best/likely/worst) anchored to KPIs buyers trust: NRR, CAC payback, and revenue per FTE.
Quantify expected payoff from operational plays. D‑Lab summarises the upside of tech‑led interventions: “Exit Potential:Up to 50% increased revenue and 25% increase in market share by integrating AI in sales and marketing practices (Letticia Adimoha), (Vorecol).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
How to package the scorecard for buyers: (1) a one‑page summary of the three valuation levers with current vs. target numbers; (2) cohort and sensitivity schedules that prove assumptions; (3) an evidence folder — dashboards, pilot results, and the remediation plan with owners and timelines. That converts promise into underwritable signals and lets buyers map multiples to achievable outcomes.
With a clear, metric‑driven scorecard in hand you can move rapidly from analysis to action: baseline the KPIs, run focused 30–90 day pilots against the highest‑impact levers, and prepare the playbook you will present to potential acquirers.
A 90‑day implementation path that moves the needle
Week 1–4: secure IP/data and stand up customer analytics
Kick off with the existential checks: IP inventory, access controls, backups, and a SOC‑2/NIST gap map. While the security team locks down identity and logging, the analytics team should stand up a lightweight customer data stack (cloud warehouse, ETL, canonical customer/product schemas) and a first‑page dashboard that answers: ARR by cohort, churn by cohort, top 20 customers by revenue, and usage signals that predict churn.
Deliverables: asset/IP register, prioritized remediation backlog (with owners), a populated analytics schema, and a green dashboard with the 5 baseline KPIs for revenue & retention.
Keep the implementation pragmatic and measurable — start with the smallest instrumentation that produces reliable cohorts and move from there. As D‑Lab recommends, apply analytics early: “Apply customer analytics to increase revenue and market share of portfolio companies.” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Week 5–8: pilot one revenue workflow (pricing or intent‑led outbound)
Pick one revenue leaver with clear measurement and short feedback loops. Two high‑probability pilots:
– Dynamic pricing pilot: activate price recommendations on a narrow set of SKUs/accounts, run controlled A/B pricing tests, track AOV, win rate and margin impact.
– Intent‑led outbound: connect buyer intent feed → SDR cadence → CRM automation and measure signal→meeting→opportunity conversion.
Structure the pilot as an experiment: hypothesis, control cohort, test cohort, success metric (e.g., +AOV, -sales cycle, +close rate), and a clear stop/go decision at day 28. Instrument everything so attribution is clean: which signal produced the meeting; which price lift produced the margin.
Use conservative, high‑impact automation to free sellers: D‑Lab notes the productivity returns from sales automation, for example “40-50% reduction in manual sales tasks. 30% time savings by automating CRM interaction (IJRPR).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
Week 9–12: scale wins, set quarterly targets, and report to IC
If the pilot hits its target, move from experiment to scale: document the playbook (data flows, prompts, vendor connectors, runbooks), replicate across adjacent products/regions, and automate roll‑out tasks (onboarding scripts, dashboards, training modules). Establish quarterly targets tied to valuation levers: NRR lift, CAC payback improvement, AOV or margin uplift, and time‑to‑value for each scaled use case.
Packaging for the investment committee: a one‑page scorecard (baseline vs target KPIs), cohort evidence, sensitivity tables (best/likely/worst), and an owners/timeline matrix. That packet converts operational wins into an underwritable narrative for buyers and sets the roadmap for the next 6–18 months.
Reminder and motivation: automation compounds when pipelines, pilots and secure data are in place — D‑Lab calls this out as a core source of value in exits: “Workflow Automation: AI agents, co‑pilots, and assistants reduce manual tasks (4050%), deliver 112457% ROI, scale data processing (300x), reduce research screening time (-10x), and improve employee efficiency (+55%).” Deal Preparation Technologies to Enhance Valuation of New Portfolio Companies — D-LAB research
When the 90 days finish, you should have secured IP and data, a working customer analytics engine, a validated revenue play with measured uplift, and a repeatable playbook that an operating partner or portfolio team can deploy at scale — the ideal setup for turning those improvements into durable EBITDA gains and a clear story for prospective buyers.
The private equity landscape for healthcare exits has become increasingly challenging, with technology infrastructure serving as a critical make-or-break factor in successful transactions. Diligize, a specialist technology advisor, has emerged as a transformative force in this space, offering comprehensive pre-exit technology due diligence and value creation services that dramatically reduce deal friction while maximizing portfolio company valuations for healthcare exits.
The company’s expertise was recently demonstrated in the high-profile Optegra acquisition by EssilorLuxottica, where Diligize served as the lead technology advisor, conducting AI-readiness assessments across Optegra’s value chain and identifying multiple upside levers that contributed to the deal’s success.
The Technology Challenge in Healthcare Private Equity Exits
Healthcare private equity exits have faced substantial headwinds, with exit deal volume remaining down 41% from 2021 peaks and Q1 2025 showing a 2-year low in both deal volume and value. Beyond traditional market factors, technology infrastructure has emerged as a critical determinant of exit success, with 1 in 5 PE professionals reporting that technology issues have been deal breakers in M&A processes.
The healthcare sector’s unique technology challenges compound these difficulties:
Regulatory complexity: Healthcare technology must navigate HIPAA, GDPR, and other stringent data protection frameworks while maintaining operational efficiency
Interoperability requirements: Systems must seamlessly integrate with EMR, EHR, and other healthcare IT ecosystems
Cybersecurity imperatives: Healthcare remains among the most targeted industries for cyberattacks, with patient data representing extraordinarily valuable targets
Legacy system limitations: Outdated core systems create scalability barriers and impose security risks that can depress exit valuations
Diligize: A Strategic Technology Partner
Company Overview and Capabilities
Diligize positions itself as “a specialist technology advisor and partner to private equity and their portfolio companies, adding value through the investment cycle”. Founded in 2014 and headquartered in London, the company operates with a presence in Madrid, Milan, and Tallinn, providing access to over 800 technology subject matter experts.
The company’s comprehensive service portfolio spans the entire investment lifecycle:
Pre-Deal Services:
Buy-side technology due diligence
Acquisition synergy analysis
Technology subject matter expertise
Deal generation based on competitive technology advantage
Post-Acquisition Services:
Technology operating model rationalization
Post-merger integration solutions
Interim management
ERP recovery projects
Exit Preparation Services:
Technology due diligence for exit readiness
Value-add transformation implementation
Independent operating model reviews
Cybersecurity assessments
The Optegra Success Story
The Optegra transaction exemplifies Diligize’s transformative impact on healthcare exits. EssilorLuxottica’s acquisition of Optegra for an undisclosed sum represents a significant milestone in EssilorLuxottica’s med-tech strategy. The deal involved over 70 eye hospitals and diagnostic facilities across five European markets (UK, Czech Republic, Poland, Slovakia, and Netherlands).
Diligize’s Role:
Mandated for sell-side technology due diligence
Conducted comprehensive AI-readiness assessments across Optegra’s value chain
Identified multiple upside levers that enhanced the acquisition’s strategic value
Applied their proprietary “alt.human” methodology to maximize technology-driven valuation
The transaction’s success demonstrates how sophisticated technology due diligence can transform a healthcare portfolio company into an irresistible acquisition target for strategic buyers.
The Diligize Advantage: Reducing Exit Friction
Comprehensive Technology Assessment
Diligize’s approach addresses the 93% of PE professionals who now proactively address technology challenges during exit planning. Their methodology encompasses:
Infrastructure and Systems Evaluation:
Assessment of scalability, security, and performance optimization
Analysis of cloud architecture, API integrations, and microservices
Identification of technical debt and modernization requirements
Cybersecurity and Compliance:
Evaluation of security vulnerabilities and encryption protocols
HIPAA, GDPR, and regulatory compliance assessment
Data protection and privacy framework analysis
AI and Digital Transformation Readiness:
Assessment of artificial intelligence implementation potential
Evaluation of data analytics capabilities
Digital transformation roadmap development
Value Creation Through Technology Enhancement
The company’s “alt.human” service represents a revolutionary approach to exit preparation, combining AI-readiness scanning with concrete value-creation blueprints that buyers can trust. This methodology delivers:
Tangible Value Levers:
Revenue engines and efficiency plays that are piloted, not just forecasted
Evidence-backed upside that can add 1-2 turns to the exit multiple
Operational improvements that enhance EBITDA performance
Risk Mitigation:
Identification and resolution of technology-related red flags
Preparation for intensive due diligence processes
Elimination of potential deal-breaking technology issues
Making Healthcare Portfolio Companies “Sexy” to Acquirers
The Attractiveness Factor in M&A
Modern acquirers, particularly strategic buyers like EssilorLuxottica, seek technology-enabled platforms that can integrate seamlessly into their existing ecosystems. Diligize’s approach transforms healthcare portfolio companies into compelling acquisition targets through:
Technology Modernization:
Upgrading legacy systems to modern, scalable platforms
Implementing AI-powered diagnostic and operational capabilities
Ensuring robust cybersecurity and compliance frameworks
Healthcare PE exits increasingly depend on technology-driven value creation rather than traditional financial engineering. Diligize’s methodology addresses this shift by:
Quantifying Technology Value:
Providing concrete metrics on technology-driven efficiency improvements
Demonstrating revenue enhancement potential through digital capabilities
Offering evidence-based valuation uplifts
Future-Proofing Investments:
Ensuring technology infrastructure can support post-acquisition growth
Implementing scalable systems that support strategic buyer objectives
Preparing for emerging healthcare technology trends
The Broader Healthcare Technology Landscape
Market Dynamics
As healthcare continues its digital transformation journey, with value-based care models and AI-powered diagnostics becoming mainstream, technology readiness will become even more critical for successful exits.
Key Market Drivers:
Aging populations requiring more efficient healthcare delivery
Regulatory requirements for digital health capabilities
Strategic buyer focus on technology-enabled platforms
Investment Thesis Validation
Healthcare technology due diligence has become essential for confirming investment theses, with experts noting that companies with topical understanding of problems often mismatch their solutions to actual needs. Diligize’s comprehensive assessment approach ensures that technology investments align with market realities and strategic objectives.
Diligize’s Competitive Advantage and Market Position: Specialized Healthcare Expertise
Unlike generalist technology consultancies, Diligize brings deep healthcare sector knowledge combined with private equity investment cycle understanding. This specialized expertise enables:
Sector-Specific Insights:
Understanding of healthcare regulatory requirements
Knowledge of industry-specific technology challenges
Expertise in healthcare data management and privacy
PE-Focused Approach:
Alignment with private equity investment timelines
Understanding of exit preparation requirements
Experience with LP return expectations
Global Reach and Local Expertise
With operations across multiple European markets and access to over 800 technology experts, Diligize can support complex international healthcare transactions while providing local market insights.
Future Outlook and Strategic Implications
Technology as a Competitive Differentiator
The healthcare M&A landscape increasingly rewards technology-enabled platforms that can demonstrate clear competitive advantages. Diligize’s approach positions portfolio companies to capitalize on this trend by:
Creating Sustainable Competitive Advantages:
Implementing technology solutions that are difficult to replicate
Establishing data-driven operational excellence
Building platforms for continuous innovation
Enabling Strategic Buyer Synergies:
Preparing systems for integration with acquirer platforms
Demonstrating technology-driven synergy potential
Reducing post-acquisition integration risks
Conclusion
Diligize represents a fundamental shift in how private equity firms approach healthcare exits. By combining deep technology expertise with healthcare sector knowledge and PE investment cycle understanding, the company transforms potentially problematic technology infrastructures into strategic assets that drive valuation uplifts and reduce deal friction.
The Optegra transaction demonstrates this transformation in action, where Diligize’s technology due diligence and AI-readiness assessment contributed to a successful strategic exit to a global healthcare technology leader. This success story illustrates how comprehensive technology preparation can make healthcare portfolio companies irresistible to strategic acquirers while maximizing returns for private equity investors.
As the healthcare M&A landscape continues to evolve, with technology infrastructure becoming increasingly critical to transaction success, Diligize’s specialized approach offers private equity firms a strategic advantage in preparing portfolio companies for successful exits. The company’s ability to reduce deal friction while enhancing portfolio company attractiveness positions it as an essential partner for healthcare-focused private equity firms seeking to maximize exit value in an increasingly competitive market.
The future of healthcare private equity exits lies in technology-enabled transformation, and Diligize has positioned itself at the forefront of this evolution, helping private equity firms unlock the full potential of their healthcare portfolio companies while delivering superior returns to their limited partners.